
El algoritmo de similitud Jaccard es un tipo muy interesante de algoritmo aplicado al análisis de grafos. Esta especialmente diseñado para calcular coeficientes de similitud tomando como base fundamental el método acuñado por Paul Jaccard.
A continuación, podrás conocer un poco más sobre cómo funciona este importante algoritmo, sus principales casos de uso y desarrollaremos un ejemplo en Neo4j que te permita comprender la funcionalidad del algoritmo de similitud Jaccard.
¿Qué es el algoritmo de similitud Jaccard?
El conocido algoritmo de similitud Jaccard es un algoritmo diseñado para aplicar los conceptos de similitud desarrollados por Paul Jaccard que ayuda a medir las similitudes entre conjuntos. Este se define como el tamaño de la intersección dividida por el tamaño de la unión de dos conjuntos. Este se rige bajo la siguiente formula:
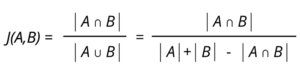
Este algoritmo desarrollado en el ambiente de trabajo de Neo4j posee dos tipos de ejecución para diferentes tipos de conjuntos de datos. Existe el análisis con base a funciones, que se utiliza normalmente para estudiar la similitud entre pequeños números de conjuntos y adicionalmente se cuenta con la ejecución del algoritmo por procedimientos que esta pensada para analizar similitudes en conjuntos de datos grandes.
Una vez comprendido esto conozcamos sus principales casos de uso.
Casos de uso del algoritmo de similitud Jaccard
Como su nombre bien lo indica, este algoritmo funciona para determinar la similitud entre dos elementos, aplicando una formula especifica. Esta nos ayuda a comprender elementos comunes entre conjuntos de datos por lo que su principal rango de utilización es formar parte de una consulta inmersa en un sistema de recomendación.

Ejemplos de aplicación
Para entender más a fondo el funcionamiento del algoritmo de similitud de Jaccard realizaremos algunos ejemplos con algunos datos. En primer lugar, calcularemos la similitud existente entre dos listas simples de números:
RETURN algo.similarity.jaccard([1,2,3], [1,2,4,5]) AS similarity
Similarity |
0.4 |
Dentro de las listas de números proporcionadas tenemos que la similitud es de 0.4. Este valor se obtiene de la aplicación de la formula del coeficiente de Jaccard que se realiza de la siguiente forma:
J(A,B) = ∣A ∩ B∣ / ∣A∣ + ∣B∣ - ∣A ∩ B|J(A,B) = 2 / 3 + 4 - 2 = 2 / 5 = 0.4
Ahora evaluemos un ejemplo un poco más complejo realizado dentro de la estructura de un grafo donde designamos algunos nodos y realizamos una consulta en Cypher.
En este ejemplo determinaremos la similitud entre dos personas en base a sus preferencias
MERGE (french:Cuisine {name:'French'})
MERGE (italian:Cuisine {name:'Italian'})
MERGE (indian:Cuisine {name:'Indian'})
MERGE (lebanese:Cuisine {name:'Lebanese'})
MERGE (portuguese:Cuisine {name:'Portuguese'})
MERGE (zhen:Person {name: "Zhen"})
MERGE (praveena:Person {name: "Praveena"})
MERGE (michael:Person {name: "Michael"})
MERGE (arya:Person {name: "Arya"})
MERGE (karin:Person {name: "Karin"})
MERGE (praveena)-[:LIKES]->(indian)
MERGE (praveena)-[:LIKES]->(portuguese)
MERGE (zhen)-[:LIKES]->(french)
MERGE (zhen)-[:LIKES]->(indian)
MERGE (michael)-[:LIKES]->(french)
MERGE (michael)-[:LIKES]->(italian)
MERGE (michael)-[:LIKES]->(indian)
MERGE (arya)-[:LIKES]->(lebanese)
MERGE (arya)-[:LIKES]->(italian)
MERGE (arya)-[:LIKES]->(portuguese)
MERGE (karin)-[:LIKES]->(lebanese)
MERGE (karin)-[:LIKES]->(italian)Una vez construido el grafo y sus relaciones internas, procedemos a ejecutar el algoritmo. Para este caso analizaremos la similitud entre dos nodos especificados en la consulta:
MATCH (p1:Person {name: 'Karin'})-[:LIKES]->(cuisine1
WITH p1, collect(id(cuisine1)) AS p1Cuisine
MATCH (p2:Person {name: "Arya"})-[:LIKES]->(cuisine2)
WITH p1, p1Cuisine, p2, collect(id(cuisine2)) AS p2Cuisine
RETURN p1.name AS from,
p2.name AS to,
algo.similarity.jaccard(p1Cuisine, p2Cuisine) AS similarityTable 7.84. Results | ||
from | To | similarity |
"Karin" | "Arya" | 0.66 |
Obtenemos como resultado que la similitud entre los nodos consultados es de 0.66.
Ejemplo de aplicación de procedimientos
Para estudiar elementos más grandes, el algoritmo de similitud de Jaccard puede aplicar procedimientos para realizar su cálculo entre todos los pares de elementos que conforman el conjunto de datos a estudiar. Este algoritmo es simétrico lo que significa que puede calcularse la similitud entre A y B de igual forma que B y A. Por lo tanto podemos calcular la similitud entre cada par de nodos de forma directa.
Utilizaremos un grafo construido de forma similar al ejemplo anterior:
MERGE (french:Cuisine {name:'French'})
MERGE (italian:Cuisine {name:'Italian'})
MERGE (indian:Cuisine {name:'Indian'})
MERGE (lebanese:Cuisine {name:'Lebanese'})
MERGE (portuguese:Cuisine {name:'Portuguese'})
MERGE (zhen:Person {name: "Zhen"})
MERGE (praveena:Person {name: "Praveena"})
MERGE (michael:Person {name: "Michael"})
MERGE (arya:Person {name: "Arya"})
MERGE (karin:Person {name: "Karin"})
MERGE (shrimp:Recipe {title: "Shrimp Bolognese"})
MERGE (saltimbocca:Recipe {title: "Saltimbocca alla roman"})
MERGE (periperi:Recipe {title: "Peri Peri Naan"})
MERGE (praveena)-[:LIKES]->(indian)
MERGE (praveena)-[:LIKES]->(portuguese)
MERGE (zhen)-[:LIKES]->(french)
MERGE (zhen)-[:LIKES]->(indian)
MERGE (michael)-[:LIKES]->(french)
MERGE (michael)-[:LIKES]->(italian)
MERGE (michael)-[:LIKES]->(indian)
MERGE (arya)-[:LIKES]->(lebanese)
MERGE (arya)-[:LIKES]->(italian)
MERGE (arya)-[:LIKES]->(portuguese)
MERGE (karin)-[:LIKES]->(lebanese)
MERGE (karin)-[:LIKES]->(italian)
MERGE (shrimp)-[:TYPE]->(italian)
MERGE (shrimp)-[:TYPE]->(indian)
MERGE (saltimbocca)-[:TYPE]->(italian)
MERGE (saltimbocca)-[:TYPE]->(french)
MERGE (periperi)-[:TYPE]->(portuguese)
MERGE (periperi)-[:TYPE]->(indian)
Aplicamos la consulta del algoritmo para estudiar todos los nodos del grafo y obtener sus intersecciones y la similitud.
MATCH (p:Person)-[:LIKES]->(cuisine)
WITH {item:id(p), categories: collect(id(cuisine))} as userData
WITH collect(userData) as data
CALL algo.similarity.jaccard.stream(data)
YIELD item1, item2, count1, count2, intersection, similarity
RETURN algo.asNode(item1).name AS from, algo.asNode(item2).name AS to, intersection, similarity
ORDER BY similarity DESC| Resultados: | |||
| From | To | Intersection | Similarity |
| Arya | Karin | 2 | 0.66 |
| Zhen | Michael | 2 | 0.66 |
| Zhen | Praveena | 1 | 0.33 |
| Michael | Karin | 1 | 0.25 |
| Praveena | Michael | 1 | 0.25 |
| Praveena | Arya | 1 | 0.25 |
| Michael | Arya | 1 | 0.2 |
| Praveena | Karin | 0 | 0 |
| Zhen | Arya | 0 | 0 |
| Zhen | Karin | 0 | 0 |
Podemos observar que existen similitudes entre varios elementos del grafo y se resalta que no hay elementos comunes entre los nodos calificados con cero en la tabla de resultados.
Esperamos que estos ejemplos permitan entender de mejor manera la funcionalidad de este algoritmo.
Visita más de Grapheverywhere para conocer todo lo que necesitas sobre algoritmos de similitud aplicados al estudio de grafos.






