
Los Panama Papers es uno de los casos de investigación y datos más importantes de los últimos tiempos. Un proceso de investigación minucioso desarrollado por la ICIJ, logró en base a una filtración de datos gigantesca, exponer redes altamente conectada de estructuras fiscales Offshore, que eran utilizadas por las élites económicas y políticas para ocultar negocios y riqueza.
Estas estructuras analizadas a través de millones de documentos, pudo rendir resultados gracias a extracciones de metadatos a través de Apache Soir y Tika. Posteriormente estos datos pudieron ser conectados y filtrados a través de grafos construidos en Neo4j y visualizados a través de Linkurious.
A continuación observaras algunos ejemplos sobre modelo de datos de grafos utilizado por el ICIJ, para el estudio de los Panama Papers.
Pasos del Análisis en cada documento
La filtración de los documentos de Mossack Fonseca que dio partida a la investigación conocida como Panama Papers, constaba de más de 11 millones de documentos. Estos datos estaban distribuidos entre Emails, bases de datos, PDFs, Imágenes, documentos de texto y algunos otros formatos de datos.
Para entender cada uno de los documentos e incluirlos a la base de datos se siguió una serie de pasos específicos que detallamos a continuación:
- Adquirir documentos
- Clasificación de documentos:
- Escaneo / OCR
- Extraer metadatos del documento
- Revisión de datos para:
- Determinar entidades y sus relaciones.
- Determinar las propiedades potenciales de la entidad y la relación
- Determinar las fuentes de esas entidades y sus propiedades.
- Elaborar estructuras de análisis, reglas, y reconocimiento de entidades con nombre para documentos
- Analizar y almacenar metadatos de documentos y relaciones entre documentos y entidades
- Analizar datos por autor, entidades nombradas, fechas, fuentes y clasificación
- Inferir relaciones de entidad
- Calcular similitudes, cobertura transitiva y triángulos.
- Analizar datos mediante consultas gráficas y visualizaciones.
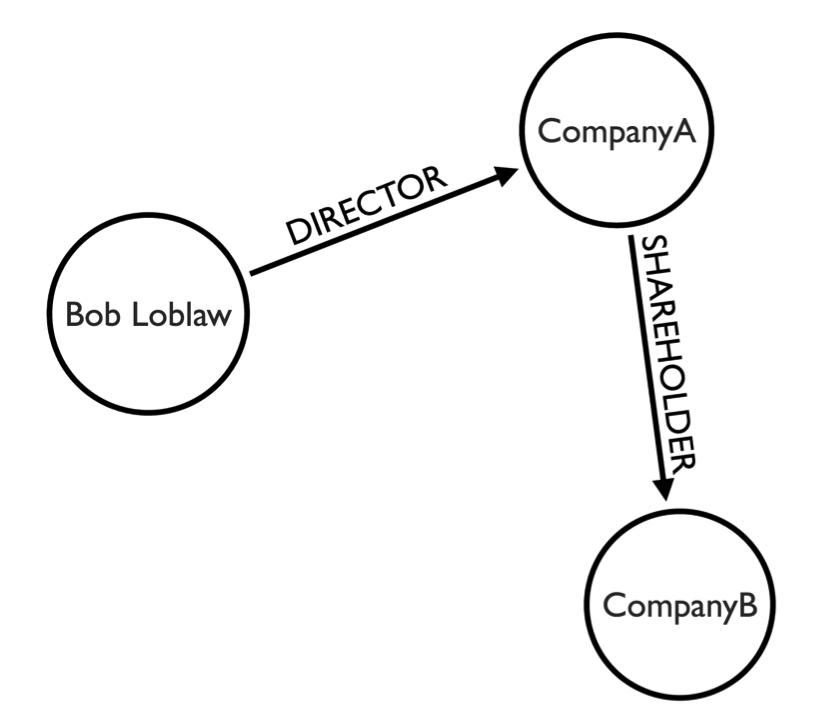
Al encontrar un modelo de tríadas para dentro del grafo, es posible demostrar una conexión inferida. Cómo es visible en la imagen, el sujeto tiene una conexión inferida con el nodo CompanyB a través del nodo signado con la nomenclatura CompanyA. Veamos ahora cómo el equipo del ICIJ gestiono la construcción de un modelo para las interrelaciones de los datos.
Modelado de interrelaciones de documentos para el grafo
En este caso tan complejo cómo el de los Panama Papers, el ICIJ creo un un modelo simple para gestionar las interrelaciones presentes entre todos los documentos. Esto cumple un rol muy importante, ya que la mayoría de estos datos contenia información de interrelaciones de tipo comercial en la que se detallan algunos datos comunes como:
- Clientes
- Empresas
- Direcciones fiscales
- ID o Nombres de Funcionarios (tanto personas físicas como empresas)
Con estas relaciones:
(:Officer)-[:is officer of]->(:Company)
Para esta categorización se incluyó:
- protector
- beneficiario, accionista, director
- beneficiario
- accionista
(:Officier)-[:registered address]->(:Address)(:Client)-[:registered]->(:Company)(:Officer)-[:has similar name and address]->(:Address)
En este caso todas estas entidades que fueron identificadas en los documentos, poseen varias propiedades como pueden ser documentos seriados, cantidades compartidas, fechas de inicio y finalización de operaciones, direcciones, nacionalidades de las personas firmantes y muchos datos más de especial relevancia.
Dos entidades con un mismo nombre, pueden llegar a tener cantidades muy diferentes de información adjunta, aunque en este caso, depende de la información relevante que fue extraída por la fuente, ya que al ser una filtración puede presumirse que hay datos incompletos. Dentro de los 2.7 Terabytes de datos gestionados por la ICIJ, podían encontrarse entidades con solo un nombre y otras con más de 15 atributos.
Las entidades que tienen relaciones especificas, como una persona que aparece como un «representante» o «funcionarios de una empresa». Esto es un dominio básico que puede completarse a partir de documentos e información sobre la participación de una empresa fantasma en un ecosistema de paraíso fiscal destacado dentro de los conocidos Panama Papers. .
Para enfrentar este alto nivel de complejidad, en principio, se procede a realizar una clasificación de documentos sin procesar por tipos o subtipos (contrato o invitación) los mismos. Posteriormente, son adjuntados todos los metadatos de forma directa o indirecta, ya sea proveniente de los tipos de documentos (remitentes o receptores de un mail, parte firmante en un contrato etc). Estos metadatos inferidos se obtiene del contenido de los documentos. Existen técnicas como el procesamiento del lenguaje natural, el reconocimiento de entidades con nombre o la búsqueda en texto sin formato de términos conocidos como nombres o roles distintivos.
El primer paso necesario para desarrollar un modelo de grafos, es extraer esas entidades que aparecen en los documentos y sus metadatos. En estos aspectos están contemplados los datos correspondientes a organizaciones, empresas y direcciones. Las entidades se convierten en nodos dentro del grafo, de esta manera se tiene que un nodo puede ser una empresa, de la que tenemos un documento de registro, datos de funcionarios y más.
Algunas relaciones se pueden inferir directamente de los documentos. En el ejemplo anterior, modelaríamos a un funcionario como un elemento conectado directamente a la empresa:
(:officerl )-[:IS_OFFICER_OF] ->(:Compañía)
Se pueden inferir otras relaciones analizando los registros de correo electrónico. Si vemos varios correos electrónicos entre una persona y una empresa podemos inferir que la persona es cliente de esa empresa:
(:CLIENT)-[:IS_CLIENT_OF]->(:Company)
Podemos utilizar una lógica similar para crear relaciones entre entidades que comparten la misma dirección, tienen vínculos familiares o relaciones comerciales o que se comunican regularmente:
- Metadatos directos -> entidades -> relaciones con documentos
- Autor, destinatarios, cuentahabiente, adjunto a, mencionado, co-ubicado
- Convierta entidades / nombres simples en registros completos utilizando registros y documentos de perfil
- Metadatos inferidos e información de otras fuentes -> Relaciones entre entidades
- Relacionado con personas u organizaciones de los metadatos directos
- Mismas direcciones / organizaciones
- Grupos comunes / anillos de pares dentro de actividades fraudulentas
- Lazos familiares, relaciones comerciales
- Parte de la cadena de comunicación
- Metadatos directos -> entidades -> relaciones con documentos
Problemas con el modelo de datos ICIJ
Para modelar tantos millones de documentos, es normal que existan algunos problemas. Especialmente relacionados con la calidad de datos. Dentro de esta base de datos existen numerosos casos de datos duplicados, pero solo algunos están conectados por una relación en la que se puede detallar si tiene un nombre o dirección similar. A mayoría de estos datos pueden ser inferidos por la primera parte de un nombre, junto con las relaciones existentes en las direcciones. Para este modelo de datos sería beneficioso también, poder fusionar realmente estos duplicados y así administrar con mayor calidad las relaciones del grafo.
En el modelo de datos del ICIJ, los datos de los accionistas de las empresas destacadas en los documentos como el número de acciones, fechas de emisión, y otros, es almacenado con la etiqueta «officer», donde este puede ser el accionista en cualquier número de empresas dentro del grafo. Para evitar problemas de duplicidad de datos esa información sobre este tipo de entidades debe ser relacionada como » “is officer of – Shareholder»
También, algunas de las propiedades boleanas podrían representarse como etiquetas, por ejemplo. “Ciudadanía = sí” podría ser una etiquera designada como: Person
¿Cómo se podría ampliar el modelo grafos básico utilizado en los Panama Papers?
El modelo de dominio utilizado por el ICIJ en los Panama Papers es realmente básico, solo contiene cuatro tipos de entidades (Oficial, Cliente, Empresa, Dirección) y cuatro relaciones entre ellas. Es una visión más o menos estática de las relaciones organizacionales, pero no incluye interacciones ni actividades. Al observar los documentos y las actividades descritas en el informe, hay muchas más cosas que podrían enriquecer este modelo de grafos para que sea más claro.
Es posible construir un modelo de grafo con los documentos originales y que estos cuenten con los metadatos y las relaciones de las personas que aparecen dentro de los conjuntos de datos. Parte de esas relaciones también son inferidas por ser parte de los datos contenidos por los documentos bajo estudio. Otras relaciones interesantes son los alias e interpretaciones de entidades que se utilizaron durante el análisis, lo que permite a otros periodistas reproducir los procesos de pensamiento originales.
Además, se pueden agregar fuentes de información adicional como registros comerciales, listas de observación u otras bases de datos periodísticas. A este modelo pueden ser incorporadas tambien relaciones que nos permitan conocer cómo los lazos familiares o comerciales de forma explícita formaron parte de la trama de operaciones financieras, así como también es posible visualizar las relaciones implícitas que infieren que los actores son parte del mismo grupo o anillo fraudulento.
Otro aspecto que falta son las actividades y el flujo de dinero. Dentro de estas relaciones podemos observar actividades de apertura o cierre de cuentas, fusión de empresas, ventas de acciones, presentación de registros entre otras. Esto permitiría tambien estudiar el flujo del dinero que rodeo a estas operaciones. Es posible rastrear los bancos, cuentas e intermediarios para que sea posible obtener una descripción general de las cantidades transferidas y los patrones de las transferencias. Luego, esos patrones se pueden aplicar para conocer los métodos de extracción de flujos de dinero fraudulentos adicionales de otros sistemas de transacciones.
Los modelos de grafos contemplan una gran flexibilidad, esto permite que al tener un punto de conexión, se cuente con la posibilidad de integrar nuevas fuentes de datos y comenzar a encontrar patrones y relaciones adicionales que antes no podía rastrear, como por ejemplo:
- Entidades nuevas:
- Documentos: E-Mail, PDF, Contrato, DB-Record,…
- Flujo de dinero: cuentas / bancos / intermediarios
- Nuevas relaciones
- Vínculos familiares / comerciales
- Conversaciones
- Grupos de pares / anillos
- Roles similares
- Menciones / Tema de
- Flujo de dinero
- Entidades nuevas:
Las ventajas de Neo4j para analizar los datos de los Panama Papers
Cómo habéis podido observar, son infinitas las posibilidades de investigación que pueden obtenerse con Neo4. Los equipos encargados de la investigación de los Panamá Papers lograron conformar modelos de datos realmente interesantes en los que pueden ejecutarse consultas de valor sobre las diferentes entidades que conforman el grafo. La calidad de las respuestas de los conjuntos de algoritmos de Neo4j nos permiten estudiar a todos los nodos de forma clara y transparente.
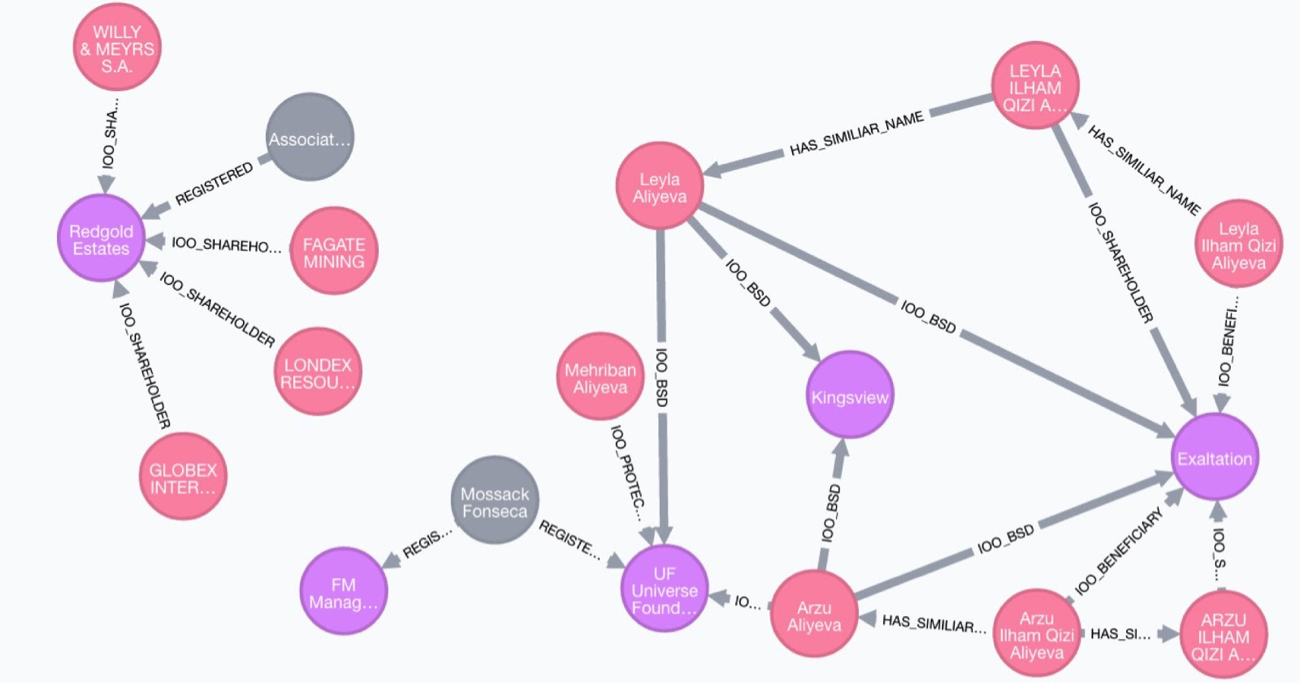
En esta investiación fue posible detectar relaciones con empresas en paraísos fiscales no solamente de políticos y famosos, sino de su vinculación a través de familiares. En el estudio de los Panama Papers los modelos de consulta y los algoritmos de caminos mas cortos y la eliminación de entidades duplicadas permitieron encontrar patrones de participación y anillos de datos conformadas por estructuras familiares y sociedades donde participaban parte de estos, en empresas, fundaciones y flujos realmente grandes de fondos.
Visita más de Grapheverywhere para descubrir todo lo que debes saber sobre los grafos.






