
El algoritmo de similitud de superposición es uno de los algoritmos que podemos encontrar en la biblioteca de Neo4j. Este se encarga de calcular, como su nombre lo indica, la similitud de superposición entre dos conjuntos de datos. A continuación conocerás más sobre este importante concepto que permite entender de mejor forma los datos contenidos en un grafo, sus principales casos de uso y desarrollaremos ejemplos prácticos en el entorno de trabajo de Neo4j para comprender a profundidad su aplicabilidad.
Veamos de que se trata el algoritmo de similitud de superposición.
¿Qué es el algoritmo de similitud de superposición?
El algoritmo de similitud de superposición esta pensado para calcular la superposición existente entre dos conjuntos de datos. Este se basa en el calculo del coeficiente de superposición, también conocido como coeficiente de Szymkiewicz-Simpson. Este concepto también esta relacionado con el índice Jaccard ya que se define como el tamaño de la intersección existente entre los datos, dividido por el conjunto de menor tamaño.
Para obtener el coeficiente de superposición debe aplicarse la siguiente formula:
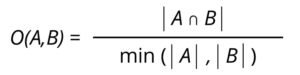
En la biblioteca de algoritmos de Neo4j están disponibles dos tipos de cálculos de este importante y funcional coeficiente de similitud. Para el desarrollo y análisis de conjuntos de datos de baja complejidad está disponible la función del algoritmo. Para grafos de volúmenes más grandes de información se cuenta con la posibilidad de desarrollar procedimientos.
Casos de uso del algoritmo de similitud de superposición
Este coeficiente es altamente funcional para estimar la similitud de superposición entre conjuntos de datos, lo que lo convierte en una herramienta de gran potencialidad para la minería de textos. Al ser de utilidad para entender conjuntos de datos y su similitud, también puede ser utilizado para formar parte de sistemas de recomendación.

Ejemplos de aplicación
Para comprender mejor la funcionalidad del algoritmo realizaremos dos ejemplos de su cálculo. En primer lugar analizaremos el desarrollo de su función en un conjunto reducido de datos con dos conjuntos de listas de números de baja dificultad. Para obtener dicho ejemplo construimos la consulta en Cypher de la siguiente forma:
RETURN algo.similarity.overlap([1,2,3], [1,2,4,5]) AS similarity
Resultados:
similarity |
|---|
| 0.66 |
Ahora bien, veamos la aplicación de la formula paso a paso, para obtener el resultado:
O(A,B) = (∣A ∩ B∣) / (min(∣A|,|B|))
O(A,B) = 2 / min(3,4)
= 2 / 3
= 0.66
Probemos realizar un análisis de mayor complejidad creando un grafo con información de mayor detalle.
Ejemplo de procedimientos del algoritmo
Para crear este ejemplo utilizaremos dos conjuntos de datos con información especifica. En estas listas incluiremos títulos de libros y categorías para clasificar por genero de literatura. Una vez construido el grafo, ejecutaremos el algoritmo para obtener un nivel de similitud entre los elementos de las listas. Veamos a continuación la composición del grafo.
MERGE (fahrenheit451:Book {title:'Fahrenheit 451'}) MERGE (dune:Book {title:'Dune'}) MERGE (hungerGames:Book {title:'The Hunger Games'}) MERGE (nineteen84:Book {title:'1984'}) MERGE (gatsby:Book {title:'The Great Gatsby'}) MERGE (scienceFiction:Genre {name: "Science Fiction"}) MERGE (fantasy:Genre {name: "Fantasy"}) MERGE (dystopia:Genre {name: "Dystopia"}) MERGE (classics:Genre {name: "Classics"}) MERGE (fahrenheit451)-[:HAS_GENRE]->(dystopia) MERGE (fahrenheit451)-[:HAS_GENRE]->(scienceFiction) MERGE (fahrenheit451)-[:HAS_GENRE]->(fantasy) MERGE (fahrenheit451)-[:HAS_GENRE]->(classics) MERGE (hungerGames)-[:HAS_GENRE]->(scienceFiction) MERGE (hungerGames)-[:HAS_GENRE]->(fantasy) MERGE (hungerGames)-[:HAS_GENRE]->(romance) MERGE (nineteen84)-[:HAS_GENRE]->(scienceFiction) MERGE (nineteen84)-[:HAS_GENRE]->(dystopia) MERGE (nineteen84)-[:HAS_GENRE]->(classics) MERGE (dune)-[:HAS_GENRE]->(scienceFiction) MERGE (dune)-[:HAS_GENRE]->(fantasy) MERGE (dune)-[:HAS_GENRE]->(classics) MERGE (gatsby)-[:HAS_GENRE]->(classics)
Ejecutamos el algoritmo y obtenemos:
MATCH (book:Book)-[:HAS_GENRE]->(genre)
WITH {item:id(genre), categories: collect(id(book))} as userData
WITH collect(userData) as data
CALL algo.similarity.overlap.stream(data)
YIELD item1, item2, count1, count2, intersection, similarity
RETURN algo.asNode(item1).name AS from, algo.asNode(item2).name AS to,
count1, count2, intersection, similarity
ORDER BY similarity DESC
Resultados:from | to | count1 | count2 | intersection | similarity |
|---|---|---|---|---|---|
| Fantasy | Science Fiction | 3 | 4 | 3 | 1.0 |
| Dystopia | Science Fiction | 2 | 4 | 2 | 1.0 |
| Dystopia | Classics | 2 | 4 | 2 | 1.0 |
| Science Fiction | Classics | 4 | 4 | 3 | 0.75 |
| Fantasy | Classics | 3 | 4 | 2 | 0.66 |
| Dystopia | Fantasy | 2 | 3 | 1 | 0.5 |
Dentro de los resultados obtenidos tenemos que la categoría de Dístopia y Fantasía tinene un nivel de similitud alto con una intersección. En este calculo mientras más bajo sea el resultado del coeficiente, más similitud entre los datos existe.
Esperamos que esta información sea de utilidad para comprender las potencialidades del algoritmo.
Visita más de Grapheverywhere para conocer todo lo que necesitas sobre los algoritmos de análisis de grafos.






