
Tratar calidad de datos con Neo4j es una experiencia muy interesante. Este potente software es capaz de ayudarnos a construir entornos de análisis de datos en grafos y estudiarlos a profundidad con su importante biblioteca de algoritmos.
Para ayudarte a comprender todas las ventajas que ofrece Neo4j en el tratamiento de los datos, recurriremos a ejecutar un ejemplo practico tomando datos de un caso bastante antiguo. Analizaremos los datos del censo irlandés desarrollado entre 1901 y 1911.
Este caso te servirá de guía para aprender a realizar tus consultas en sobre calidad de datos con Neo4j.
Calidad de datos con Neo4j aplicado al censo irlándes de 1901 a 1911
Dentro de este ejemplo práctico que desarrollaremos para que descubras las potencialidades de Neo4j para el desarrollo de modelo de calidad de datos, tomaremos como referencia los datos recogidos durante la primera decada de 1900 en Irlanda. Podéis imaginar todas las dificultades que esto puede significar debido a que estamos hablando de un procedimiento totalmente manual, donde la intervención de diferentes errores seguramente se hace presente.
En primer lugar debemos conocer la estructura básica del modelo de los datos ya que es muy lineal.
![]()
Veamos como se desarrolla este caso.
Las relaciones al principio
Para observar con claridad la complejidad del ejemplo debemos contextualizar la circunstancia en la cual han sido tomados los datos. Imaginemos 1911, los datos se toman por completo de forma analógica. Podemos sufrir de cualquier cantidad de problemas para entender y clasificar los datos, sin contar que no los formularios manuales no son totalmente seguros.
Para empezar este caso se toman aleatoriamente los documentos de datos de una familia en especifico con los datos de 1901 y se comparan con los datos de 1911
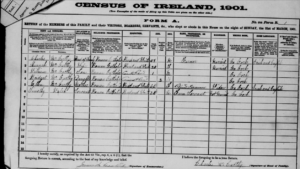
Datos de la familia McCarthy en 1901.
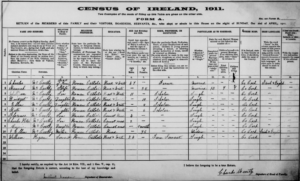
Datos de la Familia McCarthy en 1911
Transformando estos datos en una tabla comparativa obtendríamos lo siguiente:
| Surname | Forename | Age | Sex | Relation to Head | Religion | Surname | Forename | Age | Sex | Relation to Head | Religion | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| McCarthy | Charles | 37 | Male | Head of Family | Roman Catholic | McCarthy | Charles | 47 | Male | Head of Family | Roman Catholic | |
| McCarthy | Hannah | 25 | Female | Wife | Roman Catholic | McCarthy | Hannah | 35 | Female | Wife | Roman Catholic | |
| McCarthy | William | 1 | Male | Son | Roman Catholic | McCarthy | William | 11 | Male | Son | Roman Catholic | |
| McCarthy | Bridget | Female | Daughter | Roman Catholic | McCarthy | Bridget | 10 | Female | Daughter | Roman Catholic | ||
| McCarthy | Ellen | 8 | Female | Daughter | Roman Catholic | |||||||
| McCarthy | Kate | 6 | Female | Daughter | Roman Catholic | |||||||
| McCarthy | Florence | 4 | Male | Son | Roman Catholic | |||||||
| McCarthy | Charles Peter | 2 | Male | Son | Roman Catholic | |||||||
| McCarthy | Annie | Female | Daughter | Roman Catholic | ||||||||
| McCarthy | Ellen | 65 | Female | Mother | Roman Catholic | McCarthy | ? Ellen | 75 | Female | Mother | Roman Catholic | |
| Walsh | Timothy | 25 | Male | Servant | Roman Catholic | |||||||
| Regan | William |
Como podemos observar en estos registros, la familia McCarthy hacen un match perfecto entre los dos registros. Todos los miembros poseen los datos completamente registrados. Sin embargo, esto es un caso excepcional dentro de los registros de cualquier censo. Normalmente hay errores de transcripción y estos se traspasan entre los registros y afectan la veracidad de los datos.
Dentro de este conjunto de datos podemos encontrar un patrón relacional entre los datos, debido a que todos los registros están vinculados a quien aparece como «cabeza de familia». Se establecen categorías como «esposa», «hijo», «hija» y «sirviente». Pudiésemos llegar a suponer que la cabeza de familia seria siempre la misma, pero puede que el rol puede cambiar de titular por cualquier razón natural.
En primer lugar, plantearemos el proceso que vamos a realizar para encontrar coincidencias entre los residentes registrados en el censo. Empezaremos utilizando Elasticsearch como servidor, en este lugar encontraremos una copia de los datos del censo que registramos en Neo4j para tener una lista con los siguientes criterios de análisis.
¿El residente esta registrado en el censo?
¿Posee una categoría de sexo o esta vacía?
¿Los residentes mayores de 15 años tienen expectativa de ser censados en otro censo?
¿Coinciden los nombres aproximadamente en una distancia de 4 personas?
Algunos de estos resultados directamente nos indicarán cero coincidencias. Pero también tendremos candidatos de similaridad para cada uno de ellos. Crearemos un conjunto de estudio de relaciones entre el original y un registro para el candidato.
Estableciendo gráficamente los diferentes tópicos de registro tenemos un sub grafo similar al siguiente:
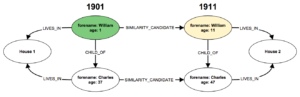
La relación entre el código «CHILD_OF» es creado cuando existe un «hijo» o una «hija» conectado a la «cabeza de familia». Podemos crear también conjuntos de relaciones para registrar matrimonios, servidumbre y otras características. Para estos casos registraremos los códigos MARRIED_TO, SIBLING_OF, NIECE_NEPHEW_OF.
En este caso de estudio el residente seleccionado tiene como nombre William. Hay una alta probabilidad de que al analizar años que al analizar la misma casa, podamos detectar similaridades en los datos o relaciones nuevas con el sujeto. En este diagrama que hemos visto existen relaciones entre los campos de CHILD OF con dos «Charles». Este vinculo los convierte en una relación SIMILARITY_CANDIDATE. Porque en este caso tenemos una alta probabilidad de encontrar dos registros de «William» que representen a la misma persona.
Como podemos apreciar esto nos da la posibilidad de establecer relaciones entre la cabeza de familia y los demás residentes del centro donde se levantaron los datos, es decir, la casa. Supongamos ahora que Charles murió en algún momento entre 1901 y 1911. Su esposa, Hanna, toma el rol de cabeza de familia. En este caso, el sub grafo que hemos visto tomará esta forma:
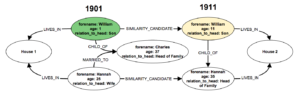
Entonces podemos decir que tenemos rutas entre -CHILD_OF-><-MARIED_TO- y -CHILD_OF- en cada uno de los extremos lo que nos permite realizar más enlaces para encontrar dentro de la casa mayores registros de relaciones del tipo SIMILARITY_CANDIDATE.
Por ejemplo los campos -CHILD_OF-><-CHILD_OF- deben ser enlazados a -CHILD_OF-><-CHILD_OF- inclusive en este caso donde la esposa se convierte en la cabeza de familia. Si por alguna circunstancia el campo delniño, toma la posición de cabeza de familia puede ser comparado con una relación del campo -SIBLING_OF-.
Ahora que hemos dejado claro las reglas de análisis, naveguemos un poco a través del código.
El código en Neo4j
Incorporando todo lo anterior a Neo4j podemos obtener un sub grafo similar al siguiente:
En este caso tenemos que el residente H1R1 (House 1, Resident 1) se compara con el H2R1 como candidato de similaridad que buscamos comparar. Así que podemos desarrollar una consulta en Neo4j de forma rápida formulando de la siguiente forma en un código del lenguaje Ruby:
def get_similarity_candidate_relationship_paths
self.query_as(:h1_r1)
.match('(h1:House), (h2:House)')
.match('h1<-[:LIVES_IN]-h1_r1-[sc_1:similarity_candidate]-(h2_r1)-[:LIVES_IN]->h2')
.match('h1<-[:LIVES_IN]-h1_r2-[sc_2:similarity_candidate]-(h2_r2)-[:LIVES_IN]->h2')
.match('path1=h1_r1-[:born_to|married_to|grandchild_of|niece_nephew_of|sibling_of
|cousin_of|child_in_law_of|step_child_of*1..2]-h1_r2')
.match('path2=h2_r1-[:born_to|married_to|grandchild_of|niece_nephew_of|sibling_of
|cousin_of|child_in_law_of|step_child_of*1..2]-h2_r2')
.pluck(
:h2_r1,
'collect([path1, rels(path1), path2, rels(path2)])'
).each_with_object({}) do |(r2, data), result|
result[r2] = data.inject(0) do |total, (path1, rels1, path2, rels2)|
relations1 = relation_string_from_path_and_rels(path1, rels1)
relations2 = relation_string_from_path_and_rels(path2, rels2)
if relations1 == relations2
1.0
elsif score = (RELATION_EQUIVILENCE_SCORES[relations1] || {})[relations2]
score
else
-2.0
end + total
end
end
endAhora empezamos con Cypher a realizar consultas a través de API de Neo4j para el objeto que hemos denominado de la siguiente forma: get_similarity_candidate_relationship_paths. Este es nuestro h1_r1. Destaca el hecho que hemos enlazado rutas entre diferentes relaciones a través de diferentes residentes de la misma casa. Así que posteriormente al devolver los datos a su lugar a través de la relación SIMILARITY_CANDIDATE todos los residentes deben estar agregados a la misma matriz.
Una vez que la consulta Cypher nos devuelve los datos que llamamos relation_string_from_path_and_rels estos se transfrorman en una ruta -BORN_TO-><-BORN_TO. Esta cadena nos brinda una manera simple de expresar el camino entre los dos residentes como una cadena.
Así podremos en este momento establecer una puntuación basada en ambas rutas o camino. Si las rutas resultasen las mismas, podemos puntuarlas como 1.0. Si el par es algo parecido a -BORN_TO-><-BORN_TO y -SIBLING_OF-> entonces podemos establecer una puntuación basada en la busqueda.
Desafíos importantes
Es importante destacar que hay procesos importantes a realizaar para que este análisis funcione correctamente. Al iniciar el ejericio práctico se ha tomado un residente a la vez para determinar todos los candidatos de similitud. Posteriormente se han creado un conjunto de relaciones que permite vincular al residente con los candidatos y almacenar los puntajes de vinculación en campos especificos de SIMILARITY_CANDIDATE y establercer de esta forma las relaciones entre los miembros de la familia.
Entonces tenemos que el primer proceso es construir las relaciones entre todos los candidatos de similitud y volver a revisar las comparaciones que nos arrojan los grafos construidos incluyendo su puntaje.
Además existe el dilema conceptual de determinar la puntuación para comparar las rutas. Acá debemos definir si alguien que esta en el campo BORN_TO fue la cabeza de familia un año, pero su consyuge se posiciona a la cabeza, esto abriria la posibilidad que BORN_TO sea una esposa en el caso de que sean hijastros. Estas condiciones hacen que los análisis sean complejos para los algoritmos.
La mayoria de los enlaces de registros como podemos observar se centran en propiedades de un objeto, pero debemos entender que las relaciones también se construyen a través de los datos que generan nuestras identidades. Con Neo4j como has podido observar podemos analizar estos datos de forma simple y rápida.
Visita más de Grapheverywhere para conocer todo el potencial de Neo4j para desarrollar procesos de Calidad de Datos.






