
Los procesos de Graph Analytics en Big Data son soluciones muy útiles para manejar y entender grandes cúmulos de datos. En tiempos recientes gracias a los procesos de Big Data podemos asimilar en segundos e inclusive en tiempo real el análisis de datos complejos sin importar su estado, estructura y lo mejor de todo podemos realizarlo en tiempo real.
Existe actualmente en el campo tecnológico una gran cantidad de herramientas que nos pueden ayudar a encontrar soluciones eficientes a problemas complejos. En esta oportunidad realizaremos un pequeño recorrido para aprovechar al máximo herramientas de Apache en combinación con el poderoso Neo4j
Graph Analytics aplicado a soluciones de Big Data
La tecnología nos permite desarrollar soluciones simples a problemas realmente complejos. Cuando surgen problemas de Big Data, necesitamos crear vías escalables que se ajusten de forma perfecta a las necesidades. Estas soluciones deben estar preparadas para ser renovables, modificables y su limite de operatividad no debe ser cercano, puesto que los datos por lo general tienden a crecer aceleradamente.
Esto es posible en parte, gracias a la capacidad de las bases de datos actuales que pueden almacenar cantidades gigantescas de datos. Pero aunque sus capacidades incrementan, presentan ciertas dificultades para flexibilizar su funcionamiento. Los modelos de datos requieren algunas transformaciones y mezclas de análisis de datos para ser efectivas. El análisis veloz y escalable de Big Data se ha convertido en una necesidad crítica para las organizaciones.
Ellas para lograr darle solución a esta necesidad se apoyan en diversas herramientas funcionales, algunas de código abierto como Apache Hadoop y Apache Spark que combinándolas con gestores de bases de datos adecuados, en especial orientados a grafos, pueden generar un análisis muy potente.
Transformando datos en gráficos
A continuación daremos un pequeño viaje sobre las potencialidades de Neo4j en combinación con herramientas de Apache para resolver problemas analíticos que podemos encontrar en proyectos de Big Data, Un ejemplo que se ajusta a la perfección a las necesidades de un proyecto de Big Data, son las soluciones en grafos que pueden desarrollarse en Neo4j. El procesamiento de gráficos a escala es realmente una característica valiosa que puede ser aprovechada. A continuación revisaremos una simulación en la que probaremos una base de datos de alto rendimiento, procesando análisis de grafos a escala.
Mazerunner para Neo4j
Mazerunner es una plataforma que permite procesar gráficos distribuidos en una extensión no administrada de Neo4j. En esta extensión se realizan trabajos de procesamiento de grafos de gran tamaño sin perder la calidad de análisis que ofrece este motor. Mazerunner utiliza una plataforma intermediaria para distribuir las cargas de procesamiento gráfico en un modulo de GraphX que se encuentra en Apache Spark.
Para desarrollar este caso de ejemplo se exportará un sub grafo de Neo4j y se escribe en Apache Hadoop. Posteriormente se exporta el subgrafo a HDFS para notificar al software Mazerunner que debe iniciar el procesamiento de los datos exportados. Este software iniciara un algoritmo de procesamiento de grafos distribuidos utilizando un modulo GraphX de Scala y Adpache Spark. El algoritmo realiza un proceso de configurar en seriales la información para compartirla con Apache Spark para iniciar su procesamiento y posteriormente redirigir toda la información a Hadoop en forma de lista clave-valor para que funcione dentro del entorno de Neo4j.
Construiremos el ejemplo con datos de películas y estructurados de la siguiente forma:
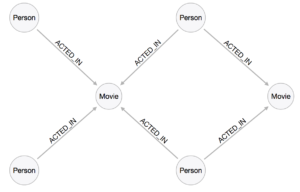
Si realizamos una transformación de este modelo y creamos relaciones entre los datos, podemos crear un grafo que nos permita determinar cuales actores, en este caso, representan un valor mayor para elegirlos para una película. La consulta en Cypher para este ejemplo se vería de la siguiente forma:
MATCH (a1:Person)-[:ACTED_IN]->(m)<-[:ACTED_IN]-(coActors)
CREATE (a1)-[:KNOWS]->(coActors);
Gracias a esta representación podemos crear un vínculo directo entre los actores. Para desarrollar el análisis de relevancia, ejecutaremos sobre los datos el algoritmo Page Rank sobre los datos que están contenidos en Apache Spark. En este caso, el software Mazerunner extiende una dirección final para ejecutar el análisis y el procesamiento de los datos de forma parecida a la siguiente:
http: // localhost: 7474 / service / mazerunner / pagerank
El Algoritmo detecta las relaciones en base a los datos que hemos ingresado, Al terminar su análisis podemos determinar resultados similares a los siguientes mediante una consulta Cypher:
neo4j-sh (?)$ MATCH n WHERE HAS(n.weight) RETURN n ORDER BY n.weight DESC LIMIT 10;
+-----------------------------------------------------------------------+
| n |
+-----------------------------------------------------------------------+
| Node[71]{name:"Tom Hanks",born:1956,weight:4.642800717539658} |
| Node[1]{name:"Keanu Reeves",born:1964,weight:2.605304495549113} |
| Node[22]{name:"Cuba Gooding Jr.",born:1968,weight:2.5655048212974223} |
| Node[34]{name:"Meg Ryan",born:1961,weight:2.52628473708215} |
| Node[16]{name:"Tom Cruise",born:1962,weight:2.430592498009265} |
| Node[19]{name:"Kevin Bacon",born:1958,weight:2.0886893112867035} |
| Node[17]{name:"Jack Nicholson",born:1937,weight:1.9641313625284538} |
| Node[120]{name:"Ben Miles",born:1967,weight:1.8680986516285438} |
| Node[4]{name:"Hugo Weaving",born:1960,weight:1.8515582875810466} |
| Node[20]{name:"Kiefer Sutherland",born:1966,weight:1.784065038526406} |
+-----------------------------------------------------------------------+
10 rows
De esta manera podemos determinar cual de los actores representa un mayor nivel de relevancia en el conjunto de datos.
Esperamos que esta información sea de utilidad para comprender las potencialidades del Graph Analytics en Big Data.
Visita más de Grapheverywhere para conocer todo lo que necesitas saber sobre Big Data.






