La analítica con grafos está siendo cada vez más usada por las entidades los organismos reguladores y las entidades financieras y es clave en la lucha contra el blanqueo de capitales.
Día a día aparecen noticias relacionadas con el Blanqueo de Capitales, un ejemplo es la institución ICIJ (International Consortium of Investigative Journalists) que ha usado una base de datos nativa de grafos para llevar a cabo sus investigaciones, entre ellas los Panamá Papers y la más recientes FINcen Files.
¿Cuál es el Valor REAL de Graph Analytics?
En definitiva se considera que el uso de los grafos son el camino a seguir para una detección e investigación más efectiva de los casos de Prevención de Blanqueo de Capitales (PBC/AML).
Según McKinsey: “estimaciones recientes muestran que aproximadamente entre 800 mil millones y 2 billones de dólares se lavan anualmente a través del sistema bancario mundial. Eso es aproximadamente del 2 al 5 por ciento del PIB mundial «.
El blanqueo de capitales también representa un costo enorme para las instituciones financieras: el cumplimiento PBC/AML cuesta $ 25,3 mil millones por año solo en los EE. UU., Según Lexis Nexis. Entre los mayores desafíos se encuentran:
- El aumento de falsos positivos que mantienen a los equipos de cumplimiento normativo ocupados con un trabajo intenso. Esto da como resultado recursos que se agotan en todas las etapas del proceso contra el lavado de dinero.
- La persistencia de falsos negativos con delincuentes inteligentes que pueden derrotar los procesos PBC/AML para cometer delitos. Se estima que en realidad se detecta tan solo el 1% de todo el dinero blanqueado.
- Los costos crecientes del cumplimiento PBC/AML que obliga a las instituciones financieras a buscar alternativas a sus herramientas y procesos actuales para evitar sanciones, penalizaciones y daños reputacionales.

Las aplicaciones tradicionales de AML y know your customer (KYC) utilizan bases de datos relacionales para almacenar datos. En las bases de datos relacionales, así como en otras NoSQL, los datos se almacenan como filas dentro de tablas. Este enfoque es muy adecuado para análisis simples, como calcular unas sumas o unos promedios.
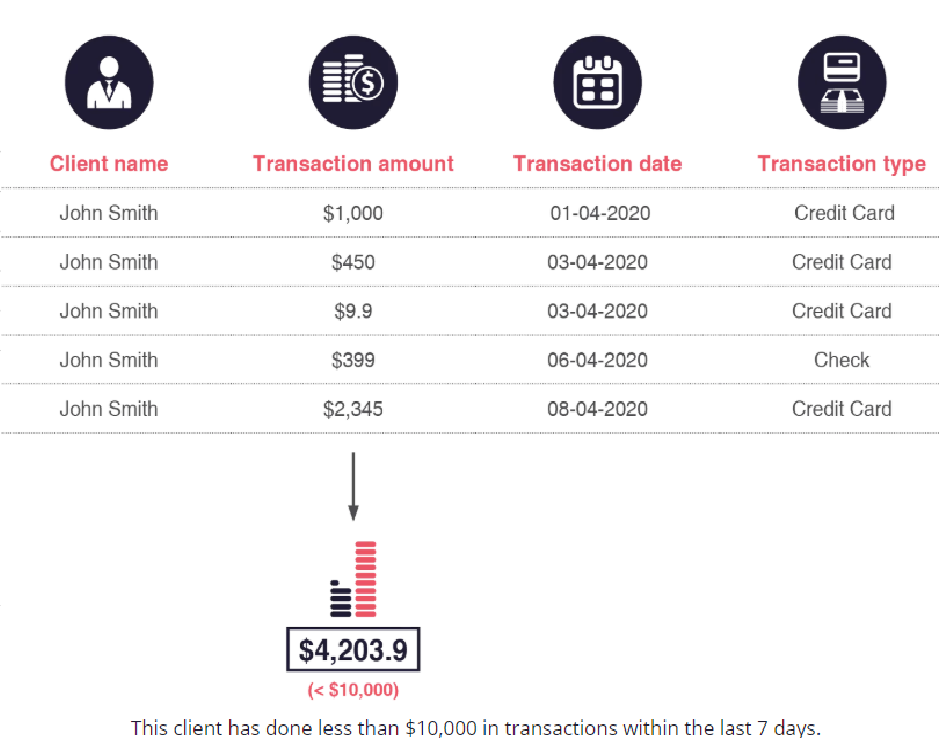
Desafortunadamente, el enfoque orientado a tablas también tiene algunas deficiencias técnicas. En primer lugar, pasar de una tabla a otra para identificar conexiones requiere de mucho tiempo. El tiempo para una consulta de este tipo aumenta exponencialmente en comparación con el número de saltos.
¿Qué significa eso?
Imaginemos una consulta simple para averiguar si la «Persona A» y la «Persona B» están conectadas o no. Si la Persona A y la Persona B solo están separadas por un número de teléfono que comparten, una base de datos relacional proporcionará una respuesta casi instantánea.
Si ambas personas están separadas por 3-4 elementos intermediarios (cuentas, teléfono, direcciones…), la respuesta será significativamente más larga, de minutos a horas. Los tiempos, además, aumentarán según el tamaño de la base de datos a la que se lanza la consulta. Si el número de intermediarios crece aún más, la respuesta se volverá poco práctica de encontrar rápidamente (con consultas que pueden tardar días en devolver resultados o nunca terminar).
Es muy relevante esta comparativa sobre estas consultas ejecutadas por sistemas relacionales versus Neo4j (base de datos nativa de grafos) sobre todo bajo la perspectiva de que el resultado en tiempo de respuesta no varía ni por el nivel de profundidad, ni por el tamaño de datos almacenados.
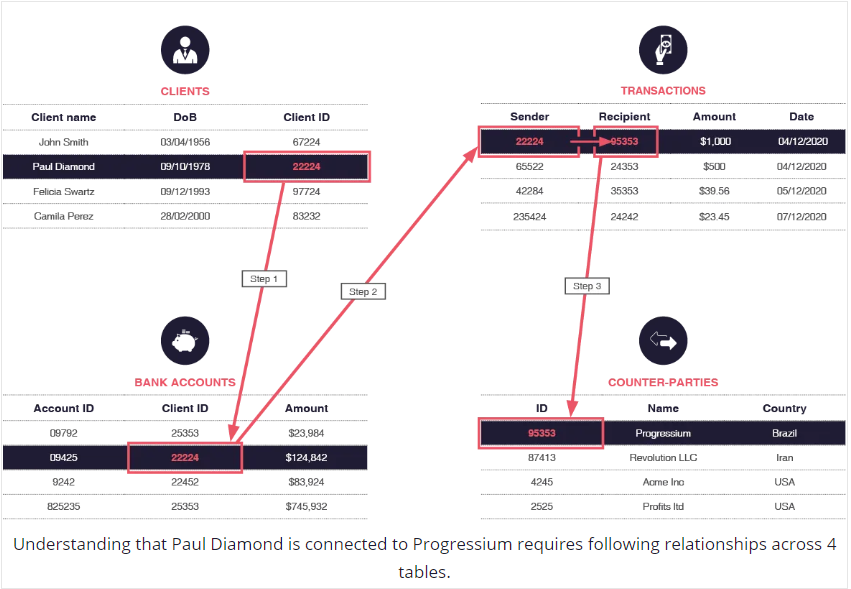
Para que quede claro, poniendo como ejemplo un estudio sobre una consulta a una red social acerca de los amigos de los amigos de los amigos .. a N niveles, queda en evidencia como las bases de datos nativas de grafos gestionan de manera excelente este reto.
La muestra es una BD de una red social con 1 millón de personas conectadas a un promedio de 50 otras personas, que da un total de 50 millones de relaciones aproximadamente.
Si esta fuera una BD relacional, tendríamos una consulta de este estilo para buscar los amigos de los amigos de una persona:

Significa poner en marcha un proceso costoso de recorrer las tablas en búsqueda de los ID que corresponden.
Una base de datos nativa de grafos, como Neo4j (que ha desarrollado un lenguaje declarativo de interrogación ad hoc) resuelve esta consulta pensando en “grafo”: accede al punto A, recorre las relaciones hacia los nodos B y sigue hasta los nodos C, para finalmente mostrar estos últimos:
Conceptualmente esta es la representación:
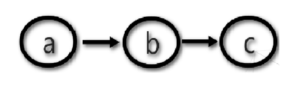
Que se traduce en una consulta Cypher (lenguaje creado por Neo4j) de este estilo:

Queda claro que el código es más intuitivo y adecuado a este tipo de consultas, pero lo mejor viene cuando empezamos a analizar los tiempos de respuesta aumentando el nivel de profundidad:
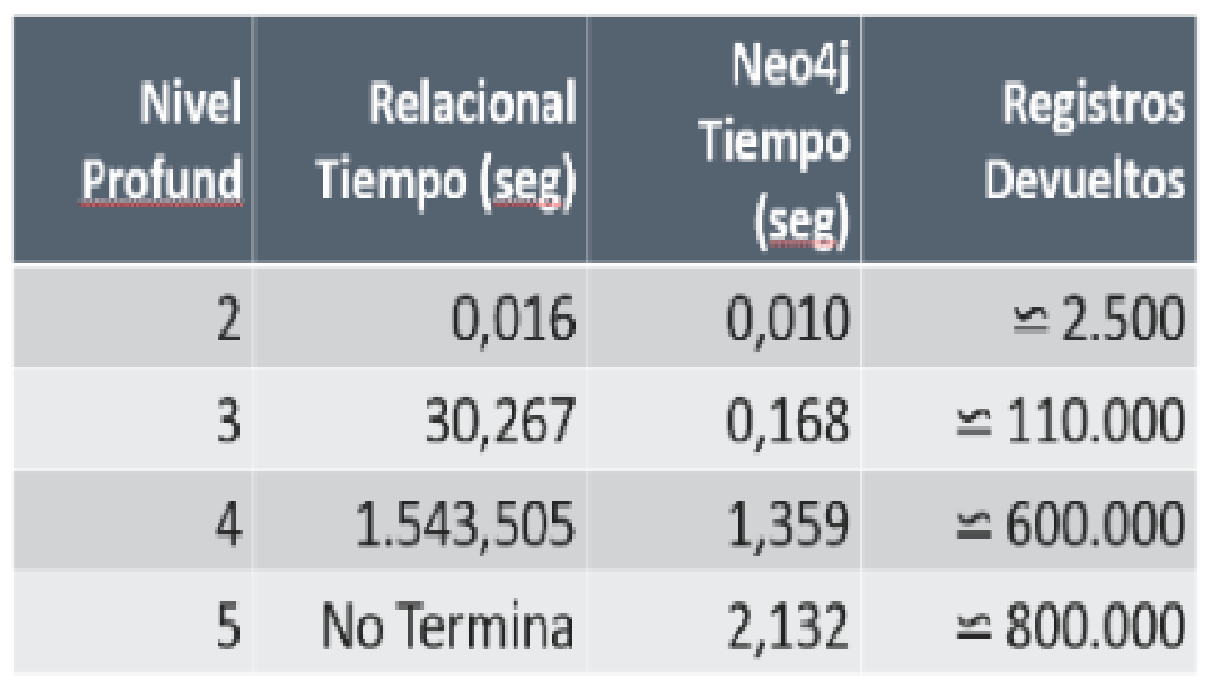
Como vemos, el tiempo de respuesta del grafo es prácticamente constante, mientras que el sistema relacional sufre un aumento de tiempo exponencial a cada aumento de saltos.
Pasamos de aproximadamente 1 centésima de segundo para un nivel 2 a 30 segundos haciendo consultas de 3 niveles, a casi ½ hora en 4 niveles … mientras que el resultado de Neo4j no es siquiera lineal frente al número de resultados, la consulta responde prácticamente en tiempo constante.
La siguiente imagen muestra esto llevado a una regla general. Las BBDD relacionales y otras NoSQL que no son nativas de grafo responden con un incremento de tiempo exponencial tanto al aumento del tamaño de la base de datos como el aumento en el número de saltos.
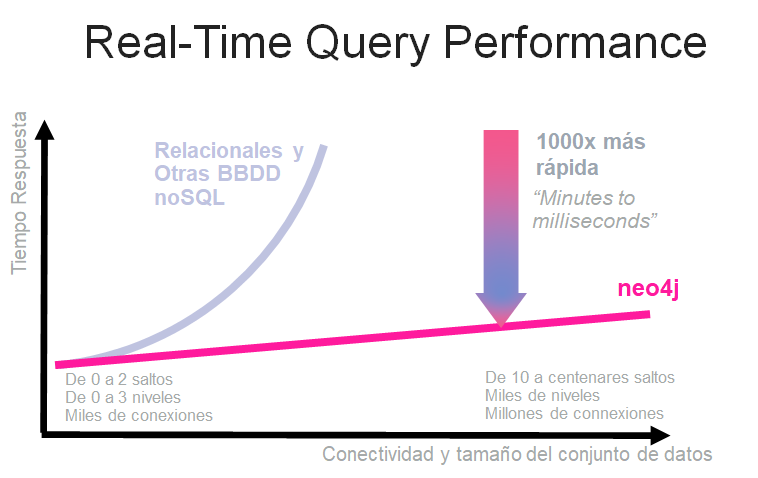
Un problema aún más insidioso es la evolución del modelo. Frente a un mundo en constante cambio, los modelos de datos han de ser capaces de evolucionar de manera ágil y esto es complicado cuando hablamos de bases de datos relacionales.
Los cambios de los modelos en bases de datos relacionales son muy costosos.
Las bases de datos relacionales no se pueden adaptar a tipos de entidades y relaciones nuevas y en evolución. Evolucionar un modelo de datos en un relacional es un proceso que implica, además, parar el sistema durante un tiempo.
Neo4j permite flexibilidad en cambios de modelo de datos con solo un comando y sin necesidad de paradas, además de poder crear o inferir relaciones a conveniencia para simplificar el modelo y facilitar la vida a los analistas y a los algoritmos analíticos.

El Enfoque de un Grafo y sus ventajas para el análisis de patrones de blanqueo de capitales
¿Qué es un grafo? Un grafo es un conjunto de nodos y relaciones.
Los grafos están a nuestro alrededor, basta pensar en cómo están estructuradas las redes de blanqueo y cómo por instinto nos lo imaginamos cuando queremos representar una investigación.
Los datos de blanqueo de capitales son inherentemente un grafo con nodos, como clientes, direcciones.. y cuentas bancarias, transacciones…, como relaciones.

En la década de los 2000 surgió un nuevo tipo de base de datos, la base de datos nativas de grafos. Como sugiere el nombre, estas bases de datos están optimizadas para datos en formato grafo. ¿Qué significa eso?
Primero, saltar de una entidad a otra es muy rápido. Abre el camino para implementar consultas más complejas y gestionan muy bien las relaciones entre elementos. En segundo lugar, el modelo grafo es particularmente flexible. Es posible agregar nuevas entidades y relaciones a sus datos en función de las necesidades de análisis.
¿Qué significa en la práctica?
La tecnología de grafos aporta 3 beneficios concretos a los profesionales de PBC:
Prioriza sus alertas actuales
Dentro de la gran cantidad de alertas generadas por la analítica tradicional, existen algunas alertas de bajo riesgo y / o valor bajo que pueden pasarse por alto.
¿Qué pasa si dentro de estas alertas, que individualmente no son importantes, hay una entidad (un cliente, un número de teléfono) que aparece varias veces? El análisis en grafo puede ayudar a detectar estas conexiones a través de alertas para que estas alertas «conectadas» tengan prioridad.
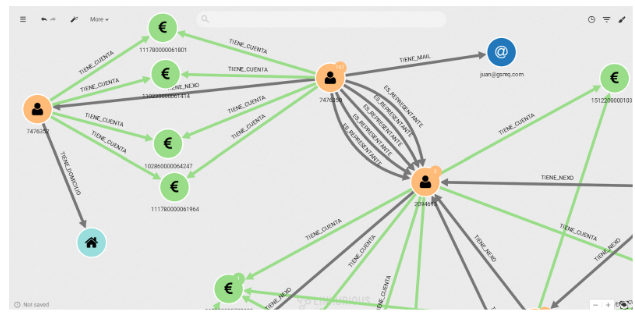
Pongamos un ejemplo práctico. Hemos cargado en neo4j información referente a la operativa de los clientes de la entidad financiera. Es información orientada a PBC, por lo que los datos de contacto de las personas, las relaciones con cuentas y sobretodo cómo se mueve el dinero entre ellas es básico. La siguiente imagen muestra una parte del modelo:
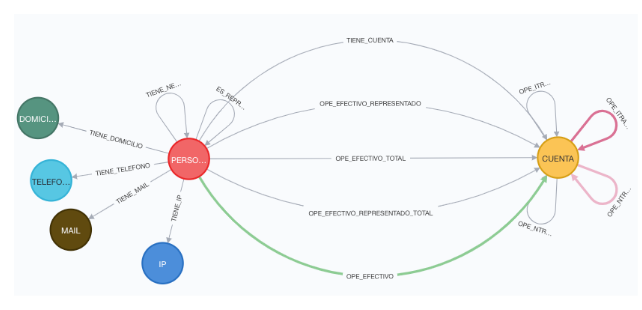
Vemos que tenemos información de operativa Nacional e Internacional, además de la de Efectivo, algo importantísimo en la PBC.
Con la tecnología de grafos podremos realizar consultas que no son viables dentro de un entorno relacional, por tiempo de ejecución y complejidad de la sintaxis. Este es un ejemplo de query compleja: queremos que se genere una alerta que nos muestre pares de personas (O-Origen, D-Destino) que cumplen con las siguientes condiciones:
- Comparten teléfono
- Comparten email
- Comparten IP desde donde se conectan
- Que O y D tienen cuentas CO y CD pero que no las comparten
- Que de la cuenta de CO sale dinero hacia una cuenta de CD pasando por una tercera cuenta intermedia que no es de ninguno de ellos dos, es decir, se cumple el patrón (CO)🡪(x)🡪(CD)
Para llevar a cabo esta consulta en un sistema relacional la base de datos tendría que realizar diversas Self-Joins que con un volumen solamente algunos pocos millones de clientes ya ralentizaría el sistema hasta hacer la consulta inviable. Además, la sentencia SQL sería bastante compleja.
Veamos cómo sería esta sentencia en Neo4j usando Cypher.
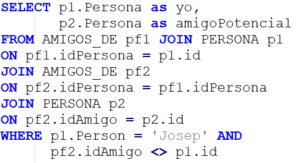
match (p1:PERSONA)-[:TIENE_TELEFONO]->(t:TELEFONO)<-[:TIENE_TELEFONO]-(p2:PERSONA), (p1:PERSONA)-[:TIENE_MAIL]->(m:MAIL)<-[:TIENE_MAIL]-(p2:PERSONA), (p1:PERSONA)-[:TIENE_IP]->(i:IP)<-[:TIENE_IP]-(p2:PERSONA) WHERE p1<>p2 with distinct p1,p2 match (p1)-[:TIENE_CUENTA]->(c1:CUENTA)-[:OPE_NTRANSF]->(c2:CUENTA)-[:OPE_NTRANSF]->(c3:CUENTA)<-[:TIENE_CUENTA]-(p2) where not exists {(p1)-[:TIENE_CUENTA]->(c2)} and not exists {(p2)-[:TIENE_CUENTA]->(c2)} and c1<>c3 with distinct p1,p2 return count(*)
En este caso el sistema ha encontrado 15 casos de estos:
match (p1:PERSONA)-[:TIENE_TELEFONO]-->(t:TELEFONO COUNT(*) 15
Veamos un ejemplo de manera visual. Aquí usamos Linkurious como herramienta de análisis y visualización del grafo.
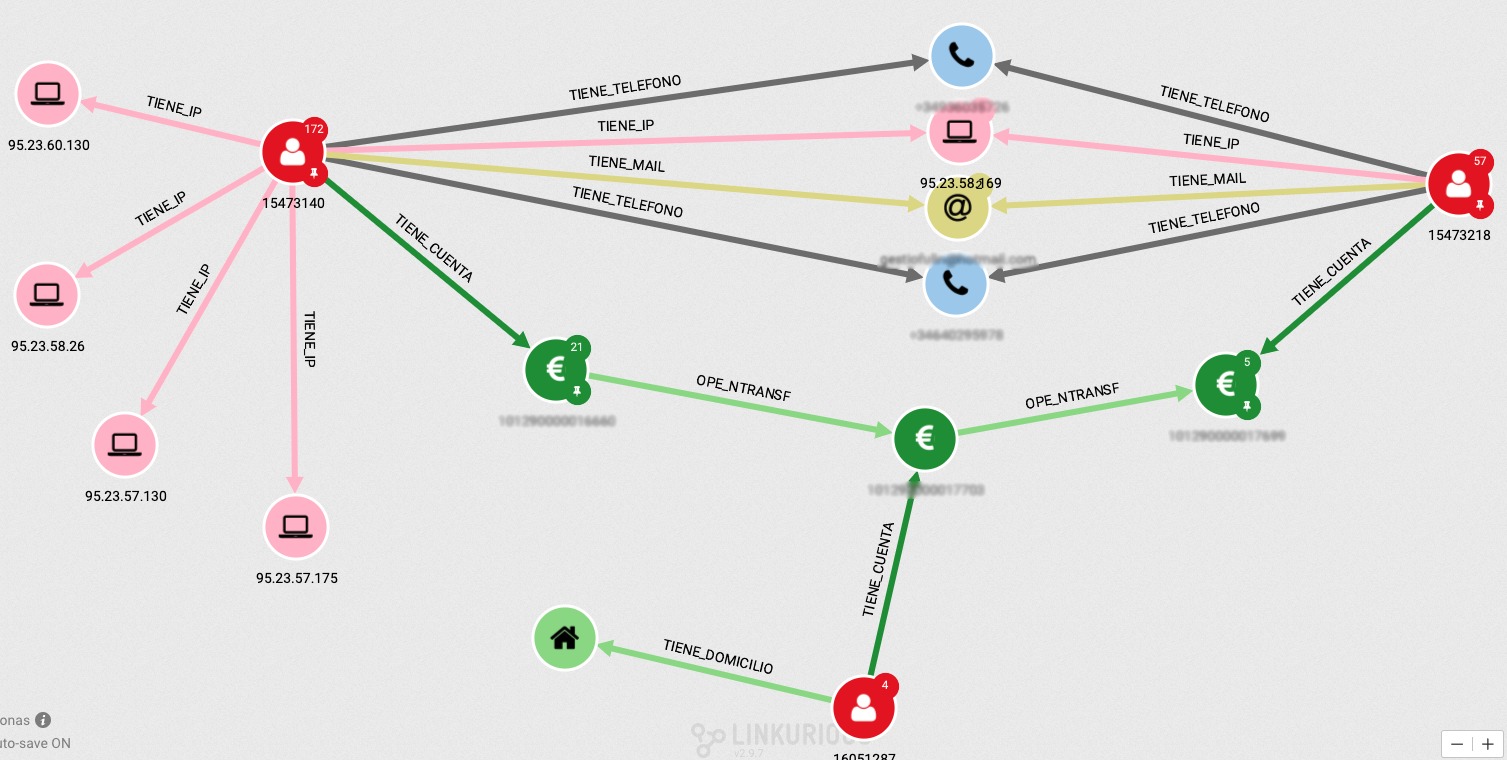
Como vemos en la imagen, es muy sencillo ver que las dos personas comparten email, IP e incluso 2 teléfonos. Además, en verde, vemos la operativa de dinero que va pasando de una cuenta a otra usando una cuenta intermedia que es de otra persona.
Esta regla se puede programar para que cada una de estas 15 Alertas sean tratadas por un técnico de blanqueo y que así puedan confirmar si realmente se trata de blanqueo o no. En caso positivo se creará un expediente que irá al organismo regulador.
Disminuye el número de falsos positivos
Al desaparecer la mayoría de las limitaciones técnicas relacionadas con la detección de patrones complejos, es posible agregar nuevas reglas que van a irse ajustando para ir reduciendo el número de falsos positivos.
Por ejemplo, puede añadirse de manera muy sencilla una regla que añada a la anterior un test de que las transacciones entre las cuentas deben sumar un monto determinado mínimo en un mes por ejemplo, o que los montos son múltiples de 100€, o cualquier otra regla más ligada a la operativa.
Vamos a ver por ejemplo esto de los montos múltiples de 100€ cómo sería en la consulta Cypher.
match (p1:PERSONA)-[:TIENE_TELEFONO]->(t:TELEFONO)<-[:TIENE_TELEFONO]-(p2:PERSONA), (p1:PERSONA)-[:TIENE_MAIL]->(m:MAIL)<-[:TIENE_MAIL]-(p2:PERSONA), (p1:PERSONA)-[:TIENE_IP]->(i:IP)<-[:TIENE_IP]-(p2:PERSONA) WHERE p1<>p2 with distinct p1,p2 match (p1)-[:TIENE_CUENTA]->(c1:CUENTA)-[t1:OPE_NTRANSF]->(c2:CUENTA)-[t2:OPE_NTRANSF]->(c3:CUENTA)<-[:TIENE_CUENTA]-(p2) where not exists {(p1)-[:TIENE_CUENTA]->(c2)} and not exists {(p2)-[:TIENE_CUENTA]->(c2)} and c1<>c3 and t1.importe % 100 = 0 and t2.importe % 100 = 0 with distinct p1,p2 return count(*)
Vemos que ahora el total de alertas se ha reducido a 8.
match(p1:PERSONA)-[:TIENE_TELEFONO]-->(t:TELEFONO)<-- count(*) 8
Acelerar las investigaciones AML
Finalmente, con más información capturada sobre las conexiones en sus datos, y con esta información accesible visualmente a través de la visualización de un grafo, los investigadores pueden dedicar menos tiempo a recopilar una vista de 360 ° de los clientes y las transacciones.
Como resultado, pueden concentrarse en tomar las decisiones correctas en mucho menos tiempo y con mucha más claridad en el momento de elaborar un reporte.
La parte de reporting es algo muy relevante ya que la representación en grafo es muy intuitiva, pero hasta ahora el grafo debía de construirse importando datos de diferentes sistemas y dibujándolo a mano, tareas muy costosas.
Una base de datos nativa de grafos puede almacenar todos los elementos de análisis y los analistas dispondrán del dataset entero para generar visualizaciones que explican una situación sospechosa de PBC de una manera extremadamente rápida comparándolo con lo que se venía haciendo hasta ahora.
A fines prácticos ¿Cómo explotar la potencia de Neo4j?
Como hemos dicho en un ejemplo arriba, la plataforma habilita un sinfín de posibilidades para los Data Scientists, que se verán beneficiados por poder lanzar consultas complejas o utilizar los algoritmos que ya existen y forman parte de la plataforma, para conseguir variables, features que podrán ser incorporadas a procesos de analítica avanzada o machine learning, como estos:
También hemos hablado de herramientas que habilitan los Analistas Funcionales ya que, sin requerir de conocimientos técnicos, pueden fácilmente y de manera intuitiva, explorar los datos.
Además también pueden recabar visualizaciones claras para incorporar en informes y/o escalar, compartir, o tomar las decisiones/acciones correspondientes, de forma rápida, precisa y bien documentada.
Linkurious es la solución más adecuada para este caso de uso. Ya hemos visto antes algunos ejemplos de visualización, pero vamos a explicar un poco más qué es lo que permite esta herramienta y por qué creemos que es muy interesante para los analistas de PBC.
Pueden realizar búsquedas y análisis de nodos concretos o pueden trabajar sobre “alertas”.
Las alertas son ejecuciones automatizadas de consultas complejas (se buscan patrones) y que devuelven avisos a los analistas para que exploren los nodos y relaciones sospechosas y determinen si el caso es positivo o no lo es.
Además, pueden compartir visualizaciones con otros usuarios, publicar y exportar a otros formatos (incluye el Excel).
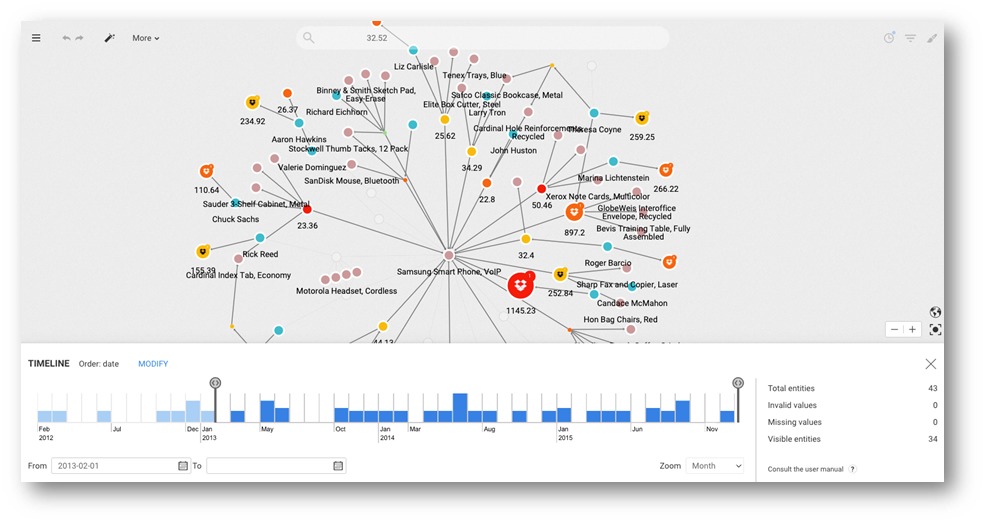
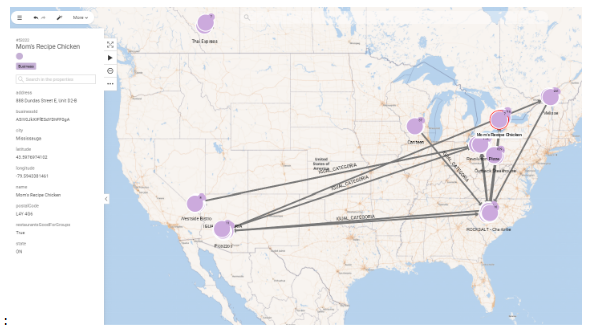
La exploración del grafo es muy rica, además se incorporan funcionalidades de muy alto valor, como la ubicación de nodos en un mapa o puede habilitarse una ventana temporal para analizar la evolución de nodos y relaciones en el tiempo (visualizar y esconder operativa por ejemplo en función de días, meses, años … ).
Conclusione sobre el uso de Grafos en la lucha contra el Blanqueo de Capitales
El análisis en grafo es una parte fundamental de las técnicas modernas contra el blanqueo de capitales. Brinda una oportunidad única para convertir la complejidad de las relaciones dentro de sus datos en un activo de alto valor para el negocio.
El equipo de Graph Everywhere está especializado en implementar este tipo de soluciones. A lo largo de este tiempo nos hemos enfocado en ayudar a los equipos de cumplimiento normativo a descubrir esquemas complejos y confiar en una imagen más holística de sus clientes para sus investigaciones.
Nos hemos convertido en aliados estratégicos de nuestros clientes y hemos aprendido mucho en el camino:
«Junto con Graph Everywhere, hemos podido desarrollar e implementar una solución de alto rendimiento para el análisis de redes de Blanqueo de Capitales.
Esta tecnología ha mejorado la efectividad del equipo de análisis de PBC, permitiéndonos realizar investigaciones que antes no eran posibles. Ahora, las necesidades regulatorias están mejor cubiertas gracias al backend Neo4j.»
Para obtener más información no dudes en contactar con nosotros aquí.






