
La tecnología de grafos es una herramienta potente para responder preguntas que provienen de modelos de datos de alta complejidad. A continuación, descubrirás algunas de las principales interrogantes sobre su funcionamiento.
Antes que nada, te recordamos que en nuestro articulo “Qué es un grafo” podéis encontrar una introducción más teórica al mundo de los grafos. Lo que descubrirás a continuación se centra directamente en la parte práctica, en la tecnología que está detrás de esta teoría y que nos permite sacar el máximo rendimiento de las relaciones entre los datos.
Bases de Datos relacionales & otras NoSQL. La dictadura de la “Tabla”
Llevamos ya bastantes décadas trabajando con sistemas relacionales. Estos gestores de datos han significado el despegue de la era digital, y han permitido implementar miles de soluciones a lo largo de este tiempo. Durante esta última década se ha ido gestando la aparición de sistemas no relacionales, los gestores de datos llamados NoSQL, que han permitido una diferenciación clarísima entre los negocios tradicionales y los que se han adaptado bien a la digitalización. Esta tecnología ha sido sin duda un motor de cambio comparable a la que supuso en su día la propia “informatización” de los procesos gracias a los sistemas relacionales.

Pero ambos sistemas tienen algo en común, son gestores de datos que se basan en el concepto de set de datos, dataset o tabla. Es decir, un conjunto de elementos que tienen la forma de columnas y de filas. Algunos de ellos almacenan los datos en filas (los relacionales más tradicionales), otros en columnas (los más adaptados a soluciones analíticas, business intelligence y demás). Y debemos preguntarnos ¿dónde están las relaciones?
Pues las relaciones son un concepto más o menos etéreo. Algunos sistemas NoSQL ni siquiera tienen el concepto de relación entre DataSets, y se especializan en alta velocidad de cálculo sobre la “tabla”. Y los Relacionales, aunque su nombre nos puede llevar a equívocos, no tienen relaciones. Creamos datos dentro de tablas con sentencias INSERT, pero para las relaciones sólo tenemos el concepto de Foreign Key o la comparativa de campos entre 2 tablas en tiempo de ejecución, pero realmente las relaciones no existen como tal persistidas en la BD.
Bases de Datos de Grafos. La democracia entre Datos y Relaciones
Por el contrario, las BBDD nativas de grafos aportan un valor completamente diferencial a lo que hemos visto hasta ahora. ¡Aquí las relaciones cuentan, y mucho! Tenemos el concepto de dato, pero también tenemos al mismo nivel el concepto de Relación entre dos datos. Ha llegado la democracia a las bases de datos. Las relaciones son un ciudadano del mismo orden que los datos.
Así como en una BD relacional tenemos tablas para almacenar elementos, aquí existe el concepto de Nodo. Un Nodo almacena la información de una entidad: Persona, Producto, … Luego está la Relación que une 2 nodos. Además, sistemas nativos de grafos como Neo4j, implementan el concepto de Property Graph, que permite que tanto los nodos como las relaciones puedan contener además propiedades. Veamos el siguiente esquema:
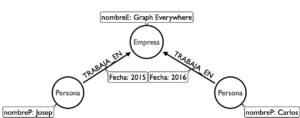
Como vemos, tenemos 2 personas (Josep y Carlos) que trabajan en la misma empresa. Y también observamos que la relación puede tener también propiedades, como en este caso la fecha desde la que Josep y Carlos trabajan en Graph Everywhere.
Por tanto, en las BBDD de grafos, además de hacer el “INSERT” de una persona, también hacemos el “INSERT” de la relación entre la persona y la empresa.
Esto significa que estos datos están físicamente ligados, físicamente persistidos en la base de datos, ahí está la salsa mágica. Esto hace que la respuesta de este motor a preguntas muy contextuales, donde se trata de analizar un dato y sus relaciones, sea dramáticamente más bajo.
Ejemplo aplicado a la realidad en una Red social
Tenemos una red social que conecta personas con personas mediante una relación de amistad. Para modelar esto con una BD relacional lo normal sería tener 2 tablas, según vemos en el siguiente esquema.
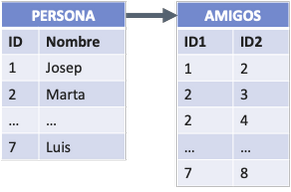
Una de las tablas contiene la información de las personas, identificadas por un ID único. La otra tabla contiene la relación de amistad entre ellas, cargando los 2 IDs relacionados. Así en el ejemplo, las personas 1 y 2 son amigos, es decir Josep y Marta, y así sucesivamente.
Ahora ya tenemos la red social cargada, vamos a preguntarle cosas al sistema. De hecho, sólo le haremos una pregunta que iremos aumentando su dificultad:
- ¿Cuáles son los amigos de los amigos de Josep? (amigos a 2 niveles)
- ¿Cuáles son los amigos de los amigos de los amigos de Josep? (3 niveles)
- … así hasta 5 niveles
Respuesta de una BBDD relacional
Para responder esta pregunta, empezando por la primera, la consulta SQL que le lanzaremos a la BD es la siguiente, por ejemplo:
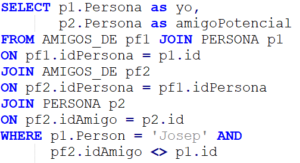
Esta consulta efectivamente nos devuelve los amigos de los amigos de Josep. No es muy bonita, pero funciona.
Respuesta de una BBDD grafo, Cypher de Neo4j
¿Cómo se haría esto en Neo4j? usaríamos Cypher, el lenguaje declarativo pensado para lanzar consultas al motor Neo4j. Es el SQL de los grafos. De hecho está en proceso de certificación para convertirse en GQL (Graph Query Language).
En este caso, el modelo de la BD sería que las personas son Nodos, y la amistad entre ellas será una Relación. Veamos la siguiente imagen:
Por ejemplo, la relación podría ser la siguiente:

Y ¿cómo le preguntamos a Neo4j por los amigos de los amigos de Josep? Veamos el código Cypher:

El resultado es el mismo que en el SQL, pero el código es bastante más simple. De Cypher ya hablamos en otras entradas del blog, ahora vamos a centrarnos en ¿qué sistema es más rápido?
Comparativa Relacional vs Grafo
Para ver cual de los dos sistemas responde mejor a esta pregunta, veamos el resto de detalles necesarios para evaluarlo. La base de datos contiene 1 millón de personas, y de media unas 50 relaciones de amistad cada una de ellas. Es decir, 50 millones de relaciones en total. En el sistema relacional significa que tenemos 1 millón de registros en la tabla Personas y 50 millones de registros en la tabla Amistad. En Neo4j esto corresponde a 1 millón de nodos Persona y 50 millones de relaciones. Veamos la comparativa en el tiempo de ejecución:
| Nivel | Relacional | Neo4j | |
| Profund | Tiempo (seg) | Tiempo (seg) | Registros Devueltos |
2 | 0,016 | 0,01 | ⋍ 2.500 |
3 | 30,267 | 0,168 | ⋍ 110.000 |
4 | 1.543,51 | 1,359 | ⋍ 600.000 |
5 | No Termina | 2,132 | ⋍ 800.000 |
Como vemos, la pregunta de nivel 2 (amigos de amigos) devuelve una respuesta más o menos igual para los dos sistemas, aproximadamente 0,01 segundos. Esta conta retorna unos 2.500 registros, que corresponden a 50×50 (50 del primer nivel y 50 del segundo). Pero ¿qué ocurre con la consulta de nivel 3?
En este caso Neo4j devuelve el resultado en 0,1 segundos, mientras que el relacional en más de 30 segundos. Para el nivel 4 el relacional tarda ya casi ½ hora. Resumiendo, el tiempo de respuesta del sistema relacional crece exponencialmente con el número de saltos, mientras que en Neo4j permanece prácticamente constante, y ni siquiera es lineal frente al volumen de datos retornados (como vemos con el nivel 5 ya prácticamente devuelve toda la BD).
Este resultado, llevado a una gráfica de coste, lo podemos ver en la siguiente imagen:
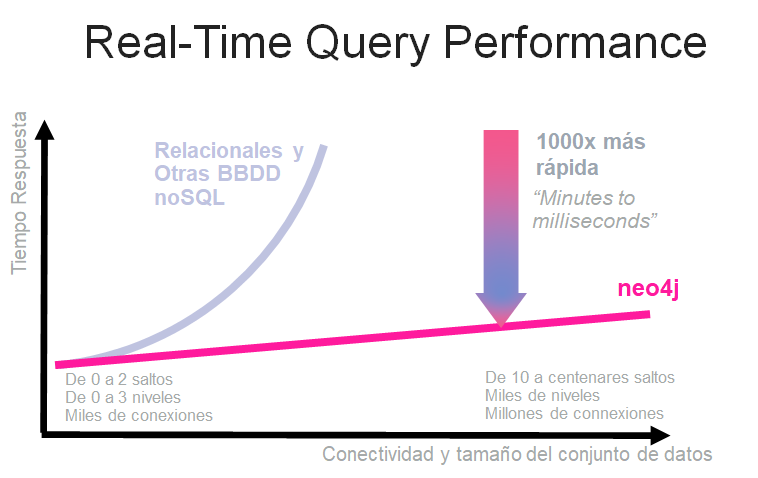
Vemos cómo el sistema relacional u otros noSQL se degradan de manera exponencial tanto al incremento del número de saltos como al incremento del volumen de la BD. Porque es importante también este segundo punto. Si la BD de ejemplo, en lugar de haber tenido 1 millón de personas tuviera 100 millones, el tiempo que tardaría Neo4j en responder estas preguntas sería exactamente el mismo, mientras que el relacional ya ni siquiera hubiera respondido bien al nivel 3 probablemente.c
¿Cómo funciona internamente Neo4j?
Neo4j dispone de 2 elementos básicos que lo hacen tan potente:
- Índices
- Index-free adjacency
El primero es bien conocido. Nos permite acceder directamente a un punto del grafo. Buscamos una persona por su ID, en el ejemplo a Josep, y si ese elemento está indexado, el motor Cypher usará el índice para acceder directamente al nodo Josep.
Una vez estamos situados en el nodo Josep, debemos recorrer el grafo, lo que se llama hacer el Traversal, y esto es lo que se hace usando la tecnología Index-free adjacency. Aquí el nodo Josep está conectado físicamente con todos sus amigos.
¿Y qué es esto del Index-free adjacency? Pues es la manera de organizar los datos para no tener que acceder a través de índices de nuevo. Veamos cómo funciona con un ejemplo.
Josep tiene que ir de su casa a la casa de Marta para entregarle un paquete. ¿Cómo lo hace en Neo4j? pues sale de su casa, y camina hacia casa de Marta. Pongamos que anda 5 min.

¿Pero cómo lo hace en un sistema relacional?
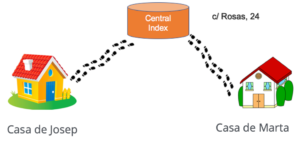
En este caso, Josep debe dirigirse primero al directorio central, donde están las direcciones de todas las personas, y luego dirigirse a casa de Marta una vez sabemos que vive en la c/ Rosas, 24. Para esto tarda 4 minutos en llegar al directorio central y otros 4 para llegar a casa de Marta, así que en total son 8 minutos, 3 más que con el sistema directo de Neo4j.
Esto es exactamente lo que hace Neo4j, conectar las entidades directamente. Y ¿cómo lo hace?
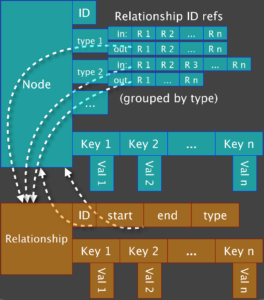
Tiene 3 almacenes:
- Node store
- Relationship store
- Property store
Cada uno de estos almacenes está compartimentado de tal manera que se puede saltar de uno a otro de manera dinámica y directa a cada objeto enlazado. Internamente se usan espacios fijos de disco para almacenar los datos, de tal modo que es más sencillo acceder a ellos y saltar entre ellos con el mínimo coste.
La importancia de los datos conectados.
Por tanto, vemos que conectar físicamente los datos nos proporciona ventajas muy grandes a nivel de rendimiento de consultas complejas. Esto aplica a multitud de casos de uso reales en nuestras organizaciones, como Data Governance, Master Data Management, Machine Learning, Sistemas de recomendación, Entity resolution, Detección del fraude, Prevención del blanqueo de capitales y otras áreas fundamentales de las que puedes aprender más visitando Grapheverywhere.






