
La duplicidad de datos es uno de los problemas más graves que debemos trabajar dentro de las estructuras de calidad de datos. Esta condición dentro de los conjuntos de datos de una empresa puede ocasionar una perdida importante de la efectividad de las decisiones que se pueden tomar. Sin embargo hay métodos y técnicas para tratar este problema y lograr depurar suficientemente nuestros datos y cumplir con las mejores condiciones de calidad posibles.
A continuación podrás conocer cómo tratar estas situaciones para que mejores la calidad de tus datos.
La Duplicidad de Datos
Dentro de un complejo conjunto de datos pueden existir diversas condiciones que vulneren la calidad de los análisis a los que son sometidos. Es por esto que las técnicas de calidad de datos cobran una importancia fundamental dentro de las estructuras organizacionales que buscan gestionar datos para producir información estratégica relevante. Como podéis imaginar existen un sin fin de causas por las que un dato puede duplicarse o generar problemas en las condiciones actuales donde el Big Data toma cualquier tipo de datos estructurado o no para analizarlo.
A continuación analizaremos un caso donde podemos encontrar duplicidad de datos. Tomaremos como referencia un proceso culinario en el cual existen diversos ingredientes y recetas que van a derivar en un sistema de recomendaciones a consumidores. Como ya puedes imaginar, tendremos algunos problemas de gestión debido a que pueden existir diversas recetas que necesiten los mismos ingredientes.
Así que en este caso tendremos que enfrentarnos a la duplicación de datos necesarios, deberemos saber como identificarlos y gestionarlos de forma eficiente y adicionalmente generar las condiciones necesarias o reglas para que los datos sean correctamente analizados.
Estudiando el problema
Para empezar con nuestro ejemplo de gestionar duplicidad de datos, podemos tomar una base de datos y hacer una consulta en Cypher sobre las recetas que incluyen un ingrediente especifico. En este caso consultaremos sobre las almendras.
La consulta sería de esta forma:
//All the ingredients that relate to almonds
MATCH (i:Ingredient)
WHERE i.name CONTAINS 'almond'
RETURN i.name as Almonds ORDER BY Almonds
El resultado que nos entregaría la base de datos sería la siguiente:
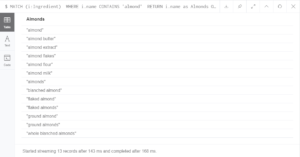
Ahora podemos notar que la consulta nos emite un conjunto de referencias que comprende desde similitudes directas en el ingrediente hasta productos un poco más elaborados y complejos. Acá se presenta una dificultad porque tenemos que enfrentarnos a datos plurales (almendra y almendras), datos con diferencias en las referencias de voz activa o pasiva y también, nuestra búsqueda con palabras adicionales.
Para encaminar una solución, debemos hacer cuenta de cuantos elementos componen el conjunto de datos que estamos estudiando. Entonces, introducimos una nueva consulta similar a la siguiente:
MATCH (n:Ingredient)
RETURN COUNT(*)Para este ejemplo, dentro de la base en la que consultamos un conjunto de datos con 3077 ingredientes.
Solucionando el problema de duplicidad
Dentro de un entorno de datos como el que explicamos anteriormente, podemos tener complicaciones de duplicidad de datos simple por términos comunes. Pero existe también una complicación donde un término pueda referirse a dos elementos distintos. Ante esto podemos necesitar establecer reglas más especificas sobre como analizar los datos.
Dentro de nuestro modelo de ejemplo podemos tener un remplazo directo de ingredientes similares. También podemos estudiar ingredientes que aparezcan con nombres diferentes o inclusive podemos necesitar construir toda una taxonomía para diferenciar todos los ingredientes similares o que pertenezcan a una misma familia.
La primera gran solución de estas múltiples complicaciones es establecer reglas claras de análisis sobre los datos. Debemos establecer parámetros que nos permitan obtener números claros de decisiones y clasificaciones entre entradas comunes de datos o datos duplicados propiamente diferenciando a través de las cualidades de los datos. Al señalar estos casos, podremos excluir directamente los datos que se dupliquen debido a errores o directamente porque cumplen con las condiciones que explicamos anteriormente.
En este ejemplo que estamos desarrollando podemos definir reglas de análisis como por ejemplo tomar «tomate» y «tomates» como el mismo tipo de dato. Adicionalmente podemos unificar como términos del mismo estilo los ingredientes que se diferencien en su nombre por pronombres activos o de pasado.
Resolver duplicidad de datos a través de la tokenización
Uno de los procesos más sencillos que podemos aplicar para resolver los conflictos de duplicidad es la tokenización de los datos. Podemos realizar esto dentro de un grafo donde creamos nodos que representen los ingredientes y los vértices indican a que nodo especifico pertenecen. A continuación podrás verlo de forma gráfica.
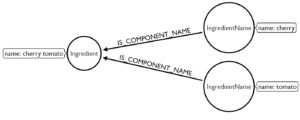
Este proceso nos permite olvidarnos de algunos de los conflictos que expresábamos en párrafos anteriores. El orden en el que realizamos la consulta ahora es irrelevante, ya que pertenecen al mismo nodo. Los términos que anteriormente se diferenciaban por la pluralidad, también dejan de preocuparnos porque están concentrado dentro de la misma categorización. Esto nos permite simplificar los procesos de analizar los datos y por ende realizar consultas para llegar a los resultados más rápido.
Así que para lograr esto ejecutamos:
MATCH (i:Ingredient)
WHERE i.name CONTAINS("’") OR i.name CONTAINS("‘") OR i.name CONTAINS("
")
SET i.name = replace(replace(replace(i.name,"’", "'" ), '‘',"'"), "
", "")Adicionalmente debemos depurar los datos y remover todos los caracteres errados para que los datos sean homogeneos.
MATCH (i:Ingredient)
WHERE i.name CONTAINS('(') OR i.name CONTAINS(')')
SET i.name = replace(replace(i.name, "(", ""), ")", "")Ahora que hemos depurado los datos de errores, procedemos a crear el token con un código como el siguiente:
MATCH (i:Ingredient)
WITH i, split(lower(i.name), ' ') AS names
FOREACH (n IN names|
MERGE (in:IngredientName {name:n})
MERGE (in)-[:IS_COMPONENT_OF]->(i)
);Esto logrará dentro de la base de datos que estamos analizando que se tome cada uno de los ingredientes de forma especifica, creando nodos para cada uno de los componentes y conectando los duplicados y similares al nodo del ingrediente original. Destaquemos que estamos aplicando el código MERGE que significa que estamos reutilizando componentes existentes y también utilizamos lower () para eliminar cualquier problema.
También podemos tener algunos nodos conectados de forma incorrecta, así que los debemos corregir de la siguiente forma:
MATCH (i:IngredientName)-[:IS_COMPONENT_OF]->(in)
WHERE i.name CONTAINS '-'
WITH i, in, split(i.name, '-') AS names
FOREACH (n IN names|
MERGE (i2:IngredientName {name:n})
MERGE (i2)-[:IS_COMPONENT_OF]->(in)
)
DETACH DELETE i;Ahora técnicamente la tokenización de los datos esta totalmente realizada, ahora empezaremos a procesar dentro del conjunto de datos de ingredientes lo nombres para filtrar por completo los duplicados. Ejecutamos lo siguiente:
MATCH (i:IngredientName)
WHERE length(i.name) <3
DETACH DELETE i;Simplificamos los datos eliminando pronombres:
MATCH (i:IngredientName)
WHERE i.name IN ['and', 'the', 'this', 'with']
DETACH DELETE i;Y eliminamos también los plurales:
MATCH (i1:IngredientName), (i2:IngredientName)
WHERE id(i1)<>id(i2)
AND (i1.name+'s' = i2.name OR
i1.name+'es'=i2.name OR
i1.name+'oes'=i2.name)
WITH i1, i2
MATCH (i1)-[:IS_COMPONENT_OF]->(in1:Ingredient),
(i2)-[:IS_COMPONENT_OF]->(in2:Ingredient)
MERGE (i1)-[:IS_COMPONENT_OF]->(in2)
DETACH DELETE i2;Es importante resaltar que estamos implementando algunos elementos que permiten evitar que comparemos el nodo de forma duplicada con si mismo, que es el utilizar WHERE id(i1)<>id(i2) dentro del código de consulta.
Para concretar nuestro manejo de duplicados dentro de la base de datos debemos aplicar consultas un poco más pesadas. Es decir, implementar algunas herramientas de mayor alcance. En este caso utilizaremos el algoritmo de similaridad de Sorensen Dice. Esto nos permitirá determinar que tan similares son dos muestras.
MATCH (n1:IngredientName),(n2:IngredientName)
WHERE id(n1) <> id(n2)
WITH n1, n2,
apoc.text.sorensenDiceSimilarity(n1.name,n2.name) as sorensenDS
WHERE sorensenDS > 0.6 AND left(n1.name,2)=left(n2.name,2)
with n1, n2
WHERE length(n1.name) <> length(n2.name)
AND (left(n1.name, length(n1.name)-1)+'ies' = n2.name OR
n1.name+'d' = n2.name OR
left(n1.name, length(n1.name)-1)+'d' = n2.name)
WITH n1, n2
MATCH (n2)-[:IS_COMPONENT_OF]->(i)
MERGE (n1)-[:IS_COMPONENT_OF]->(i)
DETACH DELETE n2;También estaremos comprobando el inicio de las palabras para asegurar que se refieren al mismo término y no eliminar por error algún dato. Así que debemos especificar de forma suficiente dentro de este algoritmo los elementos que queremos excluir. Por último pero sin restar importancia debemos intentar solucionar las diferencias existentes entre términos que pueden diferenciarse tan solo por la pronunciación, así que incluimos:
MATCH (n1:IngredientName),(n2:IngredientName)
WHERE id(n1) < id(n2)
WITH n1, n2,
apoc.text.sorensenDiceSimilarity(n1.name,n2.name) AS sorensenDS
WHERE sorensenDS > 0.92
CALL apoc.text.doubleMetaphone([n1.name, n2.name]) YIELD value
WITH n1, n2, collect(value) AS val
WHERE val[0] = val[1]
WITH n1, n2
MATCH (n2)-[:IS_COMPONENT_OF]->(i:Ingredient)
MERGE (n1)-[:IS_COMPONENT_OF]->(i)
DETACH DELETE n2;Al descomponer de esta forma las consultas podemos verificar su funcionamiento y también explicar que hemos establecido un nivel bastante estricto para trabajar si una duplicación condicionada es aceptable o no. Este nivel de duplicación podemos establecerlo de la siguiente forma:
MATCH (i:Ingredient)
WITH i, [(i)<-[:IS_COMPONENT_OF]-(in:IngredientName) | in] AS components
MATCH (i)-[:IS_COMPONENT_OF*2]-(i2)
WHERE i.name < i2.name
WITH DISTINCT i, components, i2
WHERE size((i2)<-[:IS_COMPONENT_OF]-()) = size(components)
AND all(in IN components WHERE (in)-[:IS_COMPONENT_OF]->(i2))
RETURN i.name, collect(i2.name)Esta consulta nos devuelve el siguiente resultado:

Podemos notar entonces que dentro de los datos solo 358 términos duplicados fueron tokenizados en la categoría a la que pertenecen. Ahora podemos llevar nuestro análisis a un nivel superior de complejidad para sacar máximo provecho.
Análisis de datos con comunidades de detección de duplicados
Implementando algoritmos de detección de comunidades como el algoritmo de Jaccard podemos establecer consultas para entender los niveles de similaridad entre algunos datos pertenecientes a la base de consulta. En este tipo de análisis adicionalmente podemos conseguir relaciones entre los datos tokenizados, lo que podría ser de gran ayuda para análisis de alta complejidad.
Ahora debido a que nuestra base de consultas de datos poseen estructuras más complejas, debemos también aplicar el algoritmo Louvain para crear agrupaciones especificas de los ingredientes. 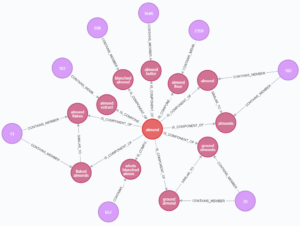 Despues de aplicado este algoritmo necesitaremos volver a hacer una consulta asociada a Jaccard dentro de la libreria de ciencia de datos en grafo (GDS por sus siglas en inglés), y debe ser de la siguiente forma:
Despues de aplicado este algoritmo necesitaremos volver a hacer una consulta asociada a Jaccard dentro de la libreria de ciencia de datos en grafo (GDS por sus siglas en inglés), y debe ser de la siguiente forma:
MATCH (p:Ingredient)<-[:IS_COMPONENT_OF]-(n)
WITH {item:id(p), categories:collect(id(n))} as itemsList
WITH collect(itemsList) as itemsToProc
CALL algo.similarity.jaccard(itemsToProc, {
writeRelationshipType: 'SIMILAR_TO',
similarityCutoff: 0.8, write:true
})
YIELD nodes, similarityPairs, write, writeRelationshipType, writeProperty, min, max, mean
RETURN nodes, similarityPairs, write, writeRelationshipType, writeProperty, min, max, mean;
Utilizando la GDS podemos cargar grafos inicialmente a Neo4j para crear grafos que se ejecuten mientras corren otras consultas y obtener cortes específicos de similaridad:
CALL gds.graph.create.cypher("similarity",
"MATCH (n) WHERE n:Ingredient OR n:IngredientName RETURN id(n) AS id",
"MATCH (i:Ingredient)<-[:IS_COMPONENT_OF]-(in:IngredientName) RETURN id(i) AS source, id(in) AS target")
En este momento ejecutamos, basándonos en las consultas de similaridad de Jaccard un nodo de similaridad:
CALL gds.nodeSimilarity.write("similarity",
{similarityCutoff:0.8,
writeRelationshipType:"SIMILAR_TO",
writeProperty:"score"})Y para finalizar excluimos de nuestra memoria del grafo el proceso de la siguiente forma:
CALL gds.graph.drop("similarity")En este caso la consulta Similar_to se relacionará con valores que tengan altos niveles de similaridad y ubicará los datos dentro de nodos pertenecientes a una misma comunidad. Ahora utilizamos nuevamente la GDS pero tomando como base el algoritmo de Louvain para consultar:
CALL algo.louvain.stream('Ingredient', 'SIMILAR_TO', {})
YIELD nodeId, community
WITH algo.getNodeById(nodeId) AS ingredient, community
MERGE (e:Entity {id:community})
MERGE (e)-[:CONTAINS_MEMBER]->(ingredient);Debemos excluir este proceso una vez hemos terminado de configurar las comunidades:
CALL gds.graph.create.cypher("community",
"MATCH (i:Ingredient) RETURN id(i) AS id",
"MATCH (i1:Ingredient)-[:SIMILAR_TO]->(i2:Ingredient) RETURN id(i1) AS source, id(i2) AS target")Y Consultamos en GDS:
CALL gds.louvain.stream("community")
YIELD nodeId, communityId
WITH gds.util.asNode(nodeId) as i, communityId
MERGE (e:Entity {id:communityId})
MERGE (e)-[:CONTAINS_MEMBER]->(i)Esto en el caso especifico que estamos desarrollando nos devuelve las siguientes agrupaciones:

Adicionalmente tenemos un valor de corte de 0.8 en las siguientes categorías:

Los resultados que obtenemos en estos casos se ajustan a los parámetros que necesitamos para que los datos sean considerados de calidad. Igualmente persisten algunos resultados con un valor de corte menor al deseado, pero que no representan problemas ya que debemos contextualizar suficientemente los datos.
Esperamos que este ejemplo te sea de utilidad para aprender a manejar la duplicidad de datos.
Visita más de Grapheverywhere para conocer más sobre calidad de datos.






